java 集群 ----1

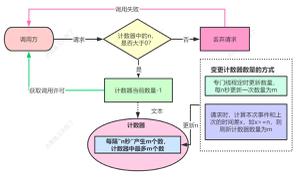
最重要的是在集群中共享一个计数器,从而选择去连接那个数据源
-----------------------1
首先来学习一下一个高并发性能的Map.ConcurrentHashMap
ConcurrentHashMap 类中包含两个静态内部类 HashEntry 和 Segment。
HashEntry 用来封装映射表的键 / 值对;
Segment 用来充当锁的角色,每个 Segment 对象守护整个散列映射表的若干个桶。
每个桶是由若干个 HashEntry 对象链接起来的链表。一个 ConcurrentHashMap 实例中包含由若干个 Segment 对象组成的数组。
(补充:一个变量声明为volatile,就意味着这个变量是随时会被其他线程修改的,因此不能将它cache在线程memory中)
如图所示结构:插入了三个节点:
ConcurrentHashMap 在默认并发级别会创建包含 16 个 Segment 对象的数组。每个 Segment 的成员对象 table 包含若干个散列表的桶。每个桶是由 HashEntry 链接起来的一个链表。如果键能均匀散列,每个 Segment 大约守护整个散列表中桶总数的 1/16。
在 ConcurrentHashMap 中,线程对映射表做读操作时,一般情况下不需要加锁就可以完成,对容器做结构性修改的操作才需要加锁。下面以 put 操作为例说明对 ConcurrentHashMap 做结构性修改的过程。
首先,根据 key 计算出对应的 hash 值:
清单 4.Put 方法的实现
|
然后,根据 hash 值找到对应的Segment 对象:
清单 5.根据 hash 值找到对应的 Segment
|
最后,在这个 Segment 中执行具体的 put 操作:
清单 6.在 Segment 中执行具体的 put 操作
|
这里的加锁操作是针对(键的 hash 值对应的)某个具体的 Segment,锁定的是该 Segment 而不是整个 ConcurrentHashMap。因为插入键 / 值对操作只是在这个 Segment 包含的某个桶中完成,不需要锁定整个ConcurrentHashMap。此时,其他写线程对另外 15 个Segment 的加锁并不会因为当前线程对这个 Segment 的加锁而阻塞。同时,所有读线程几乎不会因本线程的加锁而阻塞(除非读线程刚好读到这个 Segment 中某个 HashEntry 的 value 域的值为 null,此时需要加锁后重新读取该值)。
相比较于 HashTable 和由同步包装器包装的 HashMap每次只能有一个线程执行读或写操作,ConcurrentHashMap 在并发访问性能上有了质的提高。在理想状态下,ConcurrentHashMap 可以支持 16 个线程执行并发写操作(如果并发级别设置为 16),及任意数量线程的读操作。
以上是 java 集群 ----1 的全部内容, 来源链接: utcz.com/z/390438.html