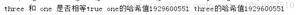java内存分配

关于Java内存分配,很多问题都模模糊糊,不能全面贯通理解。今查阅资料,欲求深入挖掘,彻底理清java内存分配脉络,只因水平有限,没达到预期效果,仅以此文对所研究到之处作以记录,为以后学习提供参考,避免重头再来。
一、Java内存分配
1、 Java有几种存储区域?
* 寄存器
-- 在CPU内部,开发人员不能通过代码来控制寄存器的分配,由编译器来管理
* 栈
-- 在Windows下, 栈是向低地址扩展的数据结构,是一块连续的内存的区域,即栈顶的地址和栈的最大容量是系统预先规定好的。
-- 优点:由系统自动分配,速度较快。
-- 缺点:不够灵活,但程序员是无法控制的。
-- 存放基本数据类型、开发过程中就创建的对象(而不是运行过程中)
* 堆
-- 是向高地址扩展的数据结构,是不连续的内存区域
-- 在堆中,没有堆栈指针,为此也就无法直接从处理器那边获得支持
-- 堆的好处是有很大的灵活性。如Java编译器不需要知道从堆里需要分配多少存储区域,也不必知道存储的数据在堆里会存活多长时间。
* 静态存储区域与常量存储区域
-- 静态存储区用来存放static类型的变量
-- 常量存储区用来存放常量类型(final)类型的值,一般在只读存储器中
* 非RAM存储
-- 如流对象,是要发送到另外一台机器上的
-- 持久化的对象,存放在磁盘上
2、 java内存分配
-- 基础数据类型直接在栈空间分配;
-- 方法的形式参数,直接在栈空间分配,当方法调用完成后从栈空间回收;
-- 引用数据类型,需要用new来创建,既在栈空间分配一个地址空间,又在堆空间分配对象的类变量;
-- 方法的引用参数,在栈空间分配一个地址空间,并指向堆空间的对象区,当方法调用完后从栈空间回收;
-- 局部变量 new 出来时,在栈空间和堆空间中分配空间,当局部变量生命周期结束后,栈空间立刻被回收,堆空间区域等待GC回收;
-- 方法调用时传入的 literal 参数,先在栈空间分配,在方法调用完成后从栈空间释放;
-- 字符串常量在 DATA 区域分配 ,this 在堆空间分配;
-- 数组既在栈空间分配数组名称, 又在堆空间分配数组实际的大小!
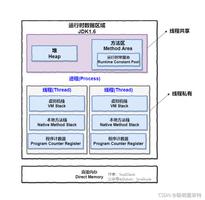
3、Java内存模型
* Java虚拟机将其管辖的内存大致分三个逻辑部分:方法区(Method Area)、Java栈和Java堆。
-- 方法区是静态分配的,编译器将变量在绑定在某个存储位置上,而且这些绑定不会在运行时改变。
常数池,源代码中的命名常量、String常量和static 变量保存在方法区。
-- Java Stack是一个逻辑概念,特点是后进先出。一个栈的空间可能是连续的,也可能是不连续的。
最典型的Stack应用是方法的调用,Java虚拟机每调用一次方法就创建一个方法帧(frame),退出该方法则对应的 方法帧被弹出(pop)。栈中存储的数据也是运行时确定的?
-- Java堆分配(heap allocation)意味着以随意的顺序,在运行时进行存储空间分配和收回的内存管理模型。
堆中存储的数据常常是大小、数量和生命期在编译时无法确定的。Java对象的内存总是在heap中分配。
4、Java内存分配实例解析
常量池(constant pool)指的是在编译期被确定,并被保存在已编译的.class文件中的一些数据。它包括了关于类、方法、接口等中的常量,也包括字符串常量。
常量池在运行期被JVM装载,并且可以扩充。String的intern()方法就是扩充常量池的一个方法;当一个String实例str调用intern()方法时,Java查找常量池中是否有相同Unicode的字符串常量,如果有,则返回其引用,如果没有,则在常量池中增加一个Unicode等于str的字符串并返回它的引用。
例:
String s1=new String("kvill");
String s2=s1.intern();
System.out.println( s1==s1.intern() );//false
System.out.println( s1+" "+s2 );// kvill kvill
System.out.println( s2==s1.intern() );//true
这个类中事先没有声名”kvill”常量,所以常量池中一开始是没有”kvill”的,当调用s1.intern()后就在常量池中新添加了一个 ”kvill”常量,原来的不在常量池中的”kvill”仍然存在。s1==s1.intern()为false说明原来的“kvill”仍然存在;s2 现在为常量池中“kvill”的地址,所以有s2==s1.intern()为true。
String 常量池问题
(1) 字符串常量的"+"号连接,在编译期字符串常量的值就确定下来, 拿"a" + 1来说,编译器优化后在class中就已经是a1。
String a = "a1";
String b = "a" + 1;
System.out.println((a == b)); //result = true
String a = "atrue";
String b = "a" + "true";
System.out.println((a == b)); //result = true
String a = "a3.4";
String b = "a" + 3.4;
System.out.println((a == b)); //result = true
(2) 对于含有字符串引用的"+"连接,无法被编译器优化。
String a = "ab";
String bb = "b";
String b = "a" + bb;
System.out.println((a == b)); //result = false
由于引用的值在程序编译期是无法确定的,即"a" + bb,只有在运行期来动态分配并将连接后的新地址赋给b。
(3) 对于final修饰的变量,它在编译时被解析为常量值的一个本地拷贝并存储到自己的常量池中或嵌入到它的字节码流中。所以此时的"a" + bb和"a" + "b"效果是一样的。
String a = "ab";
final String bb = "b";
String b = "a" + bb;
System.out.println((a == b)); //result = true
(4) jvm对于字符串引用bb,它的值在编译期无法确定,只有在程序运行期调用方法后,将方法的返回值和"a"来动态连接并分配地址为b。
String a = "ab";
final String bb = getbb();
String b = "a" + bb;
System.out.println((a == b)); //result = false
private static string getbb() {
return "b";
}
(5) String 变量采用连接运算符(+)效率低下。
String s = "a" + "b" + "c"; 就等价于String s = "abc";
String a = "a";
String b = "b";
String c = "c";
String s = a + b + c;
这个就不一样了,最终结果等于:
Stringbuffer temp = new Stringbuffer();
temp.append(a).append(b).append(c);
String s = temp.toString();
(6) Integer、Double等包装类和String有着同样的特性:不变类。
String str = "abc"的内部工作机制很有代表性,以Boolean为例,说明同样的问题。
不变类的属性一般定义为final,一旦构造完毕就不能再改变了。
Boolean对象只有有限的两种状态:true和false,将这两个Boolean对象定义为命名常量:
public static final Boolean TRUE = new Boolean(true);
public static final Boolean FALSE = new Boolean(false);
这两个命名常量和字符串常量一样,在常数池中分配空间。 Boolean.TRUE是一个引用,Boolean.FALSE是一个引用,而"abc"也是一个引用!由于Boolean.TRUE是类变量(static)将静态地分配内存,所以需要很多Boolean对象时,并不需要用new表达式创建各个实例,完全可以共享这两个静态变量。其JDK中源代码是:
public static Boolean valueOf(boolean b) {
return (b ? TRUE : FALSE);
}
基本数据(Primitive)类型的自动装箱(autoboxing)、拆箱(unboxing)是JSE 5.0提供的新功能。 Boolean b1 = 5>3; 等价于Boolean b1 = Boolean.valueOf(5>3); //优于Boolean b1 = new Boolean (5>3);
static void foo(){
boolean isTrue = 5>3; //基本类型
Boolean b1 = Boolean.TRUE; //静态变量创建的对象
Boolean b2 = Boolean.valueOf(isTrue);//静态工厂
Boolean b3 = 5>3;//自动装箱(autoboxing)
System.out.println("b1 == b2 ?" +(b1 == b2));
System.out.println("b1 == b3 ?" +(b1 == b3));
Boolean b4 = new Boolean(isTrue);////不宜使用
System.out.println("b1 == b4 ?" +(b1 == b4));//浪费内存、有创建实例的时间开销
} //这里b1、b2、b3指向同一个Boolean对象。
(7) 如果问你:String x ="abc";创建了几个对象?
准确的答案是:0或者1个。如果存在"abc",则变量x持有"abc"这个引用,而不创建任何对象。
如果问你:String str1 = new String("abc"); 创建了几个对象?
准确的答案是:1或者2个。(至少1个在heap中)
(8) 对于int a = 3; int b = 3;
编译器先处理int a = 3;首先它会在栈中创建一个变量为a的引用,然后查找有没有字面值为3的地址,没找到,就开辟一个存放3这个字面值的地址,然后将a指向3的地址。接着处理int b = 3;在创建完b的引用变量后,由于在栈中已经有3这个字面值,便将b直接指向3的地址。这样,就出现了a与b同时均指向3的情况。
5、堆(Heap)和非堆(Non-heap)内存
按照官方的说法:“Java 虚拟机具有一个堆,堆是运行时数据区域,所有类实例和数组的内存均从此处分配。堆是在Java 虚拟机启动时创建的。”
可以看出JVM主要管理两种类型的内存:堆和非堆。
简单来说堆就是Java代码可及的内存,是留给开发人员使用的;
非堆就是JVM留给自己用的,所以方法区、JVM内部处理或优化所需的内存(如JIT编译后的代码缓存)、每个类结构(如运行时常数池、字段和方法数据)以及方法和构造方法的代码都在非堆内存中。
堆内存分配
JVM初始分配的内存由-Xms指定,默认是物理内存的1/64;
JVM最大分配的内存由-Xmx指定,默认是物理内存的1/4。
默认空余堆内存小于40%时,JVM就会增大堆直到-Xmx的最大限制;空余堆内存大于70%时,JVM会减少堆直到-Xms的最小限制。
因此服务器一般设置-Xms、-Xmx相等以避免在每次GC 后调整堆的大小。
非堆内存分配
JVM使用-XX:PermSize设置非堆内存初始值,默认是物理内存的1/64;
由XX:MaxPermSize设置最大非堆内存的大小,默认是物理内存的1/4。
例子
-Xms256m
-Xmx1024m
-XX:PermSize=128M
-XX:MaxPermSize=256M
以上是 java内存分配 的全部内容, 来源链接: utcz.com/z/389936.html