每天学一点Python(2)

9月16日(python扩展的安装和使用)
接着上一篇继续。按照之前计划,先分析导出的数据,再做进一步统计。
导出的数据是html类型的,想到的处理方法有:
1.直接readlines然后一行一行找我想要的数据
2.用自带的HTMLParser分析HTML
3.用Beautifulsoup分析HTML
4.用pyquery分析HTML
5.把HTML的转成Excel,然后用xlrd分析Excel
前两种方法目前感觉有点麻烦,比较倾向于第二三种。因为后面三种办法都需要安装扩展包,所以先学习安装扩展包。
一般方法是先解压扩展包,然后用cmd到扩展包的目录下,执行python setup.py install(直接在cmd执行python需要你在环境变量path里加上python的目录)。
先进一点的方法是用easy_install,去网上搜可能找到的是ez_setup.py,在cmd里python ez_setup.py就安装好了。也可能在网上找到的安装包叫做setuptools,没有问题,其实easy_install只是setuptools的一个命令,这两种安装的结果是一样的。
把easy_install的目录也放到Path里后就可以直接用“ easy_install 扩展包”来自动下载和更新想要的扩展包了,网上的说法是他可以自己解决扩展包之间的依赖问题。但我在安装pyquery时,反复报错,仔细看了看是缺少lxml包。到这里然后搜lxml,下载安装后,即可安装pyquery。
扩展包可以通过import与from...import来使用,第一种方法是导入所有,使用时需要sys.argv这样写完整,第二种是导入一部分,假如只导入了argv,则程序里直接省去“sys.”,如果写成“from sys import *”,可以省略“sys.”并且导入所有,但不加前面那部分太容易混淆了。
9月17日(Beautifulsoup分析HTML,SQLite入门)
1.使用Beautifusoup
仔细看了看Beautifusoup和pyquery,更喜欢Beautifulsoup的风格,最后决定用他了!
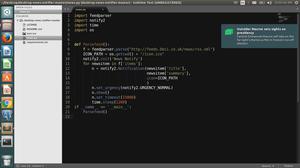
直接上代码
from bs4 import BeautifulSoupdef GetStuList(url):
doc=open(url)
soup=BeautifulSoup(doc)
StuList=[]
for i in soup.findAll('tr'):
j=i.findAll('td')tuple1=(j[2].contents[0],
j[3].contents[0],
j[4].contents[0],
j[5].contents[0],
j[6].contents[0],
j[7].contents[0],
j[8].contents[0],
j[9].contents[0],
j[11].contents[0])
StuList.append(tupple1)
return StuList
首先导入BeautifulSoup,这里一定要注意啊,按网上的写法都是from BeautifulSoup import BeautifulSoup 新版本改成bs4,写法要变成上面的,我弄了半天才发现。
然后定义方法,打开HTML文件,然后用BeautifulSoup解析。介绍两个主要方法findAll和find,一个是查找所有,一个是只查找第一个,这两个方法的前两个参数都是(name=None, attrs={}),节点名字和属性集合。然后遍历把需要的值都放在一个List里。
为了方便以后用,把段代码保存到Python根目录下getlist.py,下次直接用 import getlist就可以了。注意,一定别写成 import getlist.py。
2.SQLite入门。
我用的是windows X86版本,这里是下载地址。
直接解压就可以了,为了在cmd方便使用,放在一个简单的目录下(也可以设置Path环境变量)。SQLite真是太简洁了,非常喜欢。用两条命令来开始。
sqlite3 woody.db //在sqlite所在目录下新建一个woody数据库,如果存在就打开。sqlite> create table mytable(id integer primary key AUTOINCREMENT, name text); //新建一个表,有两列
剩下的其实就是SQL语句操作,大多数都支持。
创建表的时候假如没有令主键自动增长,插入的时候不插入主键也会自动增长,因为Sqlite中假如插入一条数据的时候主键为空,他就在现有表里找最大的主键值,然后+1。但这有可能导致删除了的主键接上继续。。所以,还是写上AUTOINCREMENT好一些。
然后用python连接数据库
import sqlite3con=sqlite3.connect("C:/sqlite/woody.db")# 连接数据库
sql=con.cousor()#创建游标
sql.execute("SELECT * FROM myTable")#执行SQL语句
sql.fetchon()#取出一条,fetchmany()是取出多条
记得连接的时候一定要写全部路径,不然会在python根目录下直接创建一个新的数据库。==#
数据库连接con有下面几个方法。
commit()#事务提交rollback()#事务回滚
close()#关闭一个数据库连接
cursor()#创建一个游标
游标sql有下面几个方法。
execute()#执行sql语句executemany#执行多条sql语句
close()#关闭游标
fetchone()#从结果中取一条记录,并将游标指向下一条记录
fetchmany()#从结果中取多条记录
fetchall()#从结果中取出所有记录
scroll()#游标滚动
参数化插入操作
for t in[(0,'woody','hahah'),(1,'hahah','hah')]:sql.execute("insert into catalog values (?,?,?)", t)
sql.commit()
9月21日
转眼都22号了,大家中秋快乐啊,三天假期经历和思考了很多,晚上仔细再写一篇。被项目拖的有些疲惫了,快一周没更新学习进度。
囧。。被项目拖着,python学习先停几天吧。
以上是 每天学一点Python(2) 的全部内容, 来源链接: utcz.com/z/388829.html