python3爬虫 - 利用浏览器cookie登录

爬虫爬网站不免遇到需要登录的问题. 登录的时候可能还会碰到需要填验证码的问题, 有的验证码甚至是拖动拼图来完成的. 虽然现在这些都有开源解决方案, 但是假设现在主要的精力想要放在如何解析html, 或者验证抓取算法上, 而不是通过登录验证上, 那么开源解决方案并不是最好的解决方案.更好的方案是获取浏览器的 Cookies, 然后让 requests 这个库来直接使用登录好的 Cookies.
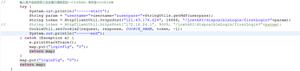
获取 Chrome 浏览器的 Cookies 信息的函数
程序在 Windows 下调试通过, 因为 C 盘需要特殊权限来读写文件, 因此程序先将 Cookies 数据库文件拷贝到当前目录.
import win32crypt 报错,请安装 pip install pypiwin32
#!/usr/bin/env python# -*- coding: utf-8 -*-
"""
__author__ = \'pi\'
__email__ = \'pipisorry@126.com\'
"""
import subprocessimport sqlite3
import win32crypt
import requests
SOUR_COOKIE_FILENAME = r\'C:\Users\pi\AppData\Local\Google\Chrome\User Data\Default\Cookies\'
DIST_COOKIE_FILENAME = \'.\python-chrome-cookies\'
def get_chrome_cookies(url):
subprocess.call([\'copy\', SOUR_COOKIE_FILENAME, DIST_COOKIE_FILENAME], shell=True)
conn = sqlite3.connect(".\python-chrome-cookies")
ret_dict = {}
for row in conn.execute("SELECT host_key, name, path, value, encrypted_value FROM cookies"):
# if row[0] not in url:
if row[0] != url:
continue
print(row[0])
ret = win32crypt.CryptUnprotectData(row[4], None, None, None, 0)
ret_dict[row[1]] = ret[1].decode()
conn.close()
subprocess.call([\'del\', \'.\python-chrome-cookies\'], shell=True)
return ret_dict
使用requests
DOMAIN_NAME = \'.jobbole.com\'get_url = r\'http://www.jobbole.com/\'
response = requests.get(get_url, cookies=get_chrome_cookies(DOMAIN_NAME))
print(response.text)
Note: 要安装requests库,安装及使用blog[python爬虫 - python requests网络请求简洁之道]
使用urllib
import urllib.requestDOMAIN_NAME = \'.jobbole.com\'
get_url = r\'http://www.jobbole.com/\'
headers = {\'Cookie\': [\'=\'.join((i, j)) for i, j in get_chrome_cookies(DOMAIN_NAME).items()][0]}
request = urllib.request.Request(get_url, headers=headers)
response = urllib.request.urlopen(request)
print(response.read().decode())
Note:
1. chrome浏览器加密后的密钥存储于%APPDATA%\..\Local\Google\Chrome\User Data\Default\Login Data"下的一个SQLite数据库中,可以通过Sqlite浏览器来查看一下登陆文件中的数据。密码是调用Windows API函数CryptProtectData来加密的。这意味着,只有用加密时使用的登陆证书,密码才能被恢复。而这根本不是问题,在用户登陆环境下执行解密就OK。SQLite数据库中password_value(是二进制数据,所以SQLite浏览器不能显示)。而破解密码,只需要调用Windows API中的CryptUnprotectData函数。[谷歌Chrome浏览器是如何存储密码的][浏览器是如何存储密码的]
2. Python为调用Windows API准备了一个完美的叫做pywin32的库。只有安装了pywin32才能调用win32crypt。安装教程见[linux和windows下安装python拓展包]
当你的输出中存在“个人主页”“退出登录”字样,就说明登录成功了,否则只会有“登录”“注册”之类的字符串。
此方法同样可以应用于知乎等等网站的登录。
皮皮Blog
获取 Chrome 浏览器的 Cookies 信息的的另一种方法
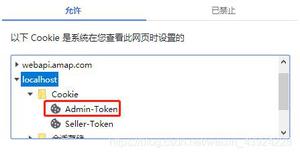
chrome > 更多工具 > javascript控制台 > 对应当前页面输入document.cookie。就可以得到当前网页的cookie相关内容,复制到代码中就可以使用了。
或者使用fiddler2,headers中找到Cookie: wordpress_logged_in_0efdf49af511fd88681529ef8c2e5fbf=*************************[cookie登录实战 - 也可以下载软件Fiddler部分]
wordpress_logged_in_0efdf49af511fd88681529ef8c2e5fbf=pipiyn%7C1440989529%7C45ec5e30a3b24a68208815cc5c572c14
get_url = r\'http://www.jobbole.com/\'cookies = {\'wordpress_logged_in_0efdf49af511fd88681529ef8c2e5fbf\': \'***username****%*******%**********\'}
response = requests.get(get_url, cookies=cookies)
print(response.text)
Note:
1. domain.com 是一级域名,www.domain.com 是域名 domain.com 的一个比较特殊的二级域名。他的特殊就在于现在的实践中,人们在解析域名的的时候,在惯例和默认的情况下,是把 www.domain.com 这个二级域名指向它的一级域名 domain.com。因此,现在的大部分情况下,domain.com 和 www.domain.com,都是一样的。 但是如果在解析域名的时候,没有做这样的设定,也可能就会有区别。
2. 不过可能document.cookie 获取到 www.domain.com 的 cookies, 而不是 .domain.com 的。
from:http://blog.csdn.net/pipisorry/article/details/47980653
ref:Python 爬虫解决登录问题的另类方法
以上是 python3爬虫 - 利用浏览器cookie登录 的全部内容, 来源链接: utcz.com/z/388623.html