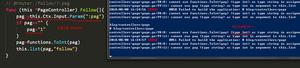
Python3 数据类型-字符串

字符串是 Python 中最常用的数据类型,是一个个字符组成的有序的序列,是字符的集合。
一 字符串定义
创建字符串很简单,可以使用引号('或"或""")来创建字符串,只要为变量分配一个值即可。
实例(Pytho3.0+):
python;gutter:true;">s1 = 'string's2 = "string2"
s3 = '''this's a "String"'''
s4 = 'hello \n magedu.com'
print(s4)
#hello
# magedu.com
s5 = r'hello \n magedu.com'
print(s5)
#hello \n magedu.com
#字符串前面加r,表示的意思是禁止字符转义
s6 = 'c:\windows\nt'
print(s6)
#c:\windows
#t
s7 = R"c:\windows\nt"
# 字符串前面加r,表示的意思是禁止字符转义
print(s7)
#c:\windows\nt
s8 = 'c:\windows\\nt'
print(s7)
#c:\windows\nt
# \ 转义字符,去除特殊字符的含义
sql = """select * from user where name='tom'"""
二 字符串元素访问
索引访问
实例(Python3.0+):
sql = "select * from user where name='tom'"print(sql[4])
# 字符串'c'
sql[4] = 'o'
# TypeError: 'str' object does not support item assignment
# 错误的,因为字符串是不可变类型
序列访问
实例(Python3.0+):
str1 = "python"for c in str1:
print(c)
print(type(c)) # 什么类型,当然还是字符串类型(str)
"""
p
<class 'str'>
y
<class 'str'>
t
<class 'str'>
h
<class 'str'>
o
<class 'str'>
n
<class 'str'>
"""
迭代访问
实例(Python3.0+):
str1 = "python"str1 = list(str1)
print(str1)
# ['p', 'y', 't', 'h', 'o', 'n']
三 字符串修改
str.replace(old.new[,count]) -> str
- 字符串中找到配皮替换为新字符串,返回新字符串
- count表示替换几次,不指定就是全部替换
实例(Python3.0+):
str1 = 'www.baidu.com'print(str1.replace('www', 'sss'))
# 'sss.baidu.com'
print(str1.replace('w', 's', 2))
# 'ssw.baidu.com'
str.strip([chars]) -> str
- 从字符串两端去除指定的字符集chars中的所有字符
- 如果chars没有指定,去除两端的空白字符及换行符
实例(Python3.0+):
s = "\r \n\t hello python \n \t"print(s.strip())
#"hello python"
s = "i am very very very sorry"
print(s.strip('iy'))
#" am very very very sorr"
str.lstrip([chars]) -> str
- 从左开始去除指定的字符集chars中的所有字符
- 如果chars没有指定,去除左边的空白字符及换行符
实例(Python3.0+):
s = "i am very very very sorry"print(s.lstrip('iy'))
#" am very very very sorry"
str.rstrip([chars]) -> str
- 从右开始去除指定的字符集chars中的所有字符
- 如果chars没有指定,去除右边的空白字符及换行符
实例(Python3.0+):
s = "i am very very very sorry"print(s.rstrip('iy'))
#"i am very very very sorr"
四 字符串查找
str.find(sub,[,start[,end]]) -> int
- 在指定的区间(start,end),从左到右,查找子串sub,找到返回索引,没找到返回-1
实例(Python3.0+):
s = "i am very very very sorry"print(s.find('very')) # 5
print(s.find('very', 5)) # 从索引5开始查找 # 5
print(s.find('very', 6, 13)) # 从索引6到13间查找 # -1
str.rfind(sub,[,start[,end]]) -> int
- 在指定的区间(start,end),从右到左,查找子串sub,找到返回索引,没找到返回-1
实例(Python3.0+):
s = "i am very very very sorry"print(s.rfind('very', 10))
print(s.rfind('very', 10, 15))
print(s.rfind('very', -10, -1)) # 15
print(s.rfind('very', -1, -10) ) # -1
str.index(sub[,start[,end]]) -> int
- 在指定的区间(start,end),从左到右,查找子串sub,找到返回索引,没找到抛出异常ValueError
一般情况下查找字符串不适用index,返回异常不容易处理,会导致程序崩溃
实例(Python3.0+):
s = "i am very very very sorry"print(s.index('very')) # 5 索引从0开始
print(s.index('very',5) )
print(s.index('very',6,13))
str.rindex(sub[,start[,end]]) -> int
- 在指定的区间(start,end),从右到左,查找子串sub,找到返回索引,没找到抛出异常ValueError
- 一般情况下查找字符串不适用index,返回异常不容易处理,会导致程序崩溃
实例(Python3.0+):
s = "i am very very very sorry"print(s.rindex('very', 10))
print(s.rindex('very', 10, 15))
print(s.rindex('very', -10, -1)) # 15
print(s.rindex('very', -1, -10)) # -1
str.count(sub[,start[,end]]) -> int
- 在指定的区间(start,end),从左到右,统计子串sub出现的次数
实例(Python3.0+):
s = 'I am very very very sorry'print(s.count('very')) # 3
print(s.count('very',5)) # 3
print(s.count('very',5,14)) # 2
五 字符串判断
str.endswith(suffix[,start[,end]]) -> bool
- 在指定区间(start,end),字符串是否是suffix结尾
str.startswith(suffix[,start[,end]]) -> bool
- 在指定区间(start,end),字符串是否是suffix开头
实例(Python3.0+):
s = "i am very very very sorry""""
首先打印出每个字符的索引:
方法1:
num = 0
for i in s:
print(num,"-",i,end="")
num +=1
# 0 - i 1 - 2 - a 3 - m 4 - 5 - v 6 - e 7 - r 8 - y 9 - 10 - v 11 - e 12 - r 13 - y 14 - 15 - v 16 - e 17 - r 18 - y 19 - 20 - s 21 - o 22 - r 23 - r 24 - y
方法2:
for i,j in enumerate(s):
print(i,"-",j,end=" ")
# 0 - i 1 - 2 - a 3 - m 4 - 5 - v 6 - e 7 - r 8 - y 9 - 10 - v 11 - e 12 - r 13 - y 14 - 15 - v 16 - e 17 - r 18 - y 19 - 20 - s 21 - o 22 - r 23 - r 24 - y
"""
print(s.startswith('very'))
# False
print(s.startswith('very', 5))
# True
print(s.startswith('very', 5, 9))
# True
print(s.endswith('very', 5, -1))
# False
print(s.endswith('very', 5, 100))
# True
is系列
六 字符串切割
str.split(sep=None,maxsplit=-1) -> list of
- 从左到右
- seq指定分割字符串,缺省的情况下空白字符串(一个或多个空白字符)作为分隔符
- maxsplit指定分割的次数,-1表示遍历整个字符串(默认是-1)
实例(Python3.0+):
s1 = "i'm \ta super student"print(s1.split())
# ["i'm", 'a', 'super', 'student']
# \t 在默认的情况下被当成分隔符(\t表示Tab键)
print(s1.split(' '))
# ["i'm", '\ta', 'super', 'student']
print(s1.split(' ', maxsplit=2))
# ["i'm", '\ta', 'super student']
print(s1.split('\t', maxsplit=2))
# ["i'm ", 'a super student']
str.rsplit(sep=None,maxsplit=-1) -> list of strings
- 从右往左切割
- sep指定分割字符串,缺省的情况下空白字符串作为分隔符
- maxsplit指定分割次数,-1表示遍历整个字符串(默认是-1)
实例(Python3.0+):
s1 = "i'm \ta super student"print(s1.rsplit())
# ["i'm", 'a', 'super', 'student']
# \t 在默认的情况下被当成分隔符
print(s1.rsplit('super'))
# ["i'm \ta ", 'uper ', 'tudent']
print(s1.rsplit(' '))
# ["i'm", '\ta', 'super', 'student']
print(s1.rsplit(' ', maxsplit=2)) #或 print(s1.rsplit(' ', 2))
# ["i'm", '\ta', 'super student'] maxsplit可以省却,直接写值
print(s1.rsplit('\t', maxsplit=2))
# ["i'm ", 'a super student']
str.splitlins([keepnds]) -> list of strings
- 按照行来切割字符串
- keepends指的是是否保留行分割符,默认不保留分隔符
- 行分割符包括\n \r\n \r等
实例(Python3.0+):
str1 = 'ab c\n\nde fg\rkl\r\n'print(str1.splitlines())
#['ab c', '', 'de fg', 'kl']
print(str1.splitlines(True))
#['ab c\n', '\n', 'de fg\r', 'kl\r\n']
s1 = """i'm a super student.
you're a super teacher."""
print(s1)
#i'm a super student.
#you're a super teacher.
print(s1.splitlines())
#["i'm a super student.", "you're a super teacher."]
print(s1.splitlines(True))
#["i'm a super student.\n", "you're a super teacher."]
str.partition(sep) -> (head,sep,tail)
- 从左至右,遇到分隔符就把字符串分割成两部分,返回头、分隔符、尾三部分的三元组;如果没有找到分隔符,就返回头、2个空元素的三元组
- sep 分隔字符串,必须指定
实例(Python3.0+):
s1 = "i'm a super student"print(s1.partition('s'))
# ("i'm a","s","uper student")
print(s1.partition(' '))
#("i'm", ' ', 'a super student')
print(s1.partition('abc'))
# ("i'm a super student",'','')
str.rpartition(sep) -> (head,sep,tail)
- 从右到左,遇到分隔符就把字符串分割成两部分,返回头、分隔符、尾三部分的三元组;如果没有找到分隔符,就返回头、2个空元素的三元组
- sep 分隔字符串,必须指定
实例(Python3.0+):
str1 = "I am supper student"print(str1.rpartition(" "))
# ('I am supper', ' ', 'student')
七 字符串大小写
str.upper()
- 把字符串中的字符转换成大写
实例(Python3.0+):
str1 = "i am a supper student"print(str1.upper())
# I AM A SUPPER STUDENT
str.lower()
- 把字符串中的字符转换成小写
- 只能转换26个英文字母,特殊字符无法转换
实例(Python3.0+):
str1 = "I AM A SUPPER STUDENT"print(str1.lower())
# i am a supper student
str.casefold()
- 把字符串中的字符转换成小写
- 比之lower,可以转换特殊字符
实例(Python3.0+):
S1 = "Runoob EXAMPLE....WOW!!!" # 英文S2 = "ß" # 德语
print(S1.lower())
# runoob example....wow!!!
print(S1.casefold())
# runoob example....wow!!!
print(S2.lower())
# ß
print(S2.casefold()) # 德语的"ß"正确的小写是"ss"
# ss
str.swapcase()
- 把字符串中的大写转换成小写,小写字符转换成大写
实例(Python3.0+):
str1 = "I Am A Supper Student"print(str1.swapcase())
#i aM a sUPPER sTUDENT
八 字符串排版
str.title() -> str
- 标题的每个单词首字母大写
str.capitalize() -> str
- 首个字母大写
实例(Python3.0+):
str1 = "i am supper student"print(str1.title())
#I Am Supper Student
print(str1.capitalize())
#I am supper student
center(width[,fillchar]) -> str
- width 打印宽度
- fillchar 填充的字符
实例(Python3.0+):
s1 = 'abc'print(s1.center(50,'#'))
#'#######################abc########################'
zfill(width) -> str
- width 打印宽度,居右,左边用0填充
实例(Python3.0+):
s1 = 'abc'print(s1.zfill(50))
'00000000000000000000000000000000000000000000000abc'
ljust(width[,fillchar]) -> str
- width 打印宽度,左对齐,右边默认空格填充
- fillchar 填充字符
实例(Python3.0+):
s1 = "abc"print(s1.ljust(20))
#"abc "
print(s1.ljust(20,"*"))
#abc*****************
rjust(width[,fillchar]) -> str
- width 打印宽度,右对齐,左边默认空格填充
- fillchar 填充字符
实例(Python3.0+):
s1 = 'abc'print(s1.rjust(20))
#" abc"
print(s1.rjust(50,"$"))
#'$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$abc'
以上是 Python3 数据类型-字符串 的全部内容, 来源链接: utcz.com/z/388611.html