新手篇丨Python任意网段Web端口信息探测工具

你学习Python的目的是什么?是想写爬虫爬取数据(数据、图片等内容),还是想自写自动化的小工具,又或是作为一个新手小白单纯的欣赏这门语言呢?
今天i春秋分享的是一篇关于多线程工具的文章,工具使用效率高,代码也比较完善,非常适合新手学习,阅读用时约5分钟。
涉及知识点
多线程模板:threading多线程模块、Queue队列模块、超时处理、异常处理。
IP地址块转换:扫描的是一个比较大的网段的IP的Web端口,我们并不能手动一个一个的输入IP地址,所以需要IP地址块和IP的转换。
HTTP网络请求库:requests模块。
正则表达式:需要在Request请求之后的Response中获取我们想要的banner信息。
思路如下:
首先,将输入的IP段转换为IP依次放入队列Queue中,之后开启多线程,将Queue传入多线程类,多线程类中的核心函数执行步骤:
1、取出一个IP并拼接URL为http://x.x.x.x的格式
2、使用requests模块获取页面status信息、title信息、banner信息(服务器的banner信息,在这里为Web容器以及其版本信息)
3、title信息需要在页面源代码中获取,并且使用re模块正则匹配title标签内的内容。
4、banner信息需要获取Response中header信息中的server。
之后,加入我们的工具文档以及自定义的LOGO信息后,一个完整的工具就完成了。
放一下完成之后的效果图:
核心代码讲解
核心代码区域也就是取出每个IP之后的工作。
[Python] 纯文本查看 复制代码
while not self._queue.empty():
ip = self._queue.get(timeout=0.5)
url = 'http://' + ip
try:
r = requests.Session().get(url=url, headers=header, timeout=5)
content = r.text
status = r.status_code
title = re.search(r'<title>(.*)</title>', content)
if title:
title = title.group(1).strip().strip(" ").strip(" ")[:30]
else:
title = "None"
banner = 'Not Found'
try:
banner = r.headers['Server'][:20]
except:
pass
sys.stdout.write("|%-16s %-6s %-26s %-30s " % (ip, status, banner, title))
except:
pass
status是http页面的状态码,简单了解http协议的童鞋应该都知道吧。
title是请求页面的标题信息,需要用正则表达式匹配一下。
banner是Response头信息中的Server字段。
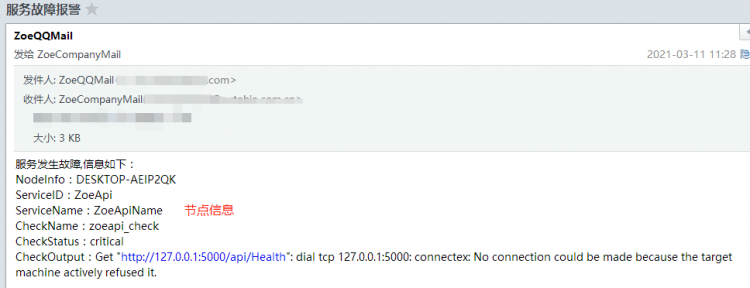
下面给出一个Request请求的Response包,可以直观看出,红框就是我们想要获取的东西。
输出使用了sys.write来解决多线程输出不对称问题,并且使用格式化输出使获取的数据对齐。
添加工具模块
Logo的制作使用Linux下的工具figlet,帮助文档使用Python内置模块argparse。
两款工具详解传送门:
https://bbs.ichunqiu.com/thread-31231-1-1.html
Logo代码以及帮助文档代码:
输出演示:
完成。
脚本运行示例:
[AppleScript] 纯文本查看 复制代码
python httpbannerscan.py -t 100 -i 192.168.1.1/24
后续改进
众所周知的是Web端口可并不仅限于80端口,一些其他的Web端口的安全性可能远不如80端口做的好。
所以,我们在使用requests模块进行request请求时,完全可以将一些常见的Web端口放进一个列表里,首先对端口的开放性进行检测,之后再抓取Response信息,这是最快速的检测方法。
常见的Web端口:
[AppleScript] 纯文本查看 复制代码
80-90,8080-8090
以上是今天的全部内容,大家学会了吗?
以上是 新手篇丨Python任意网段Web端口信息探测工具 的全部内容, 来源链接: utcz.com/z/388533.html