Python抓取优酷视频(下):使用web.py搭建网站框架

承上:
上篇已经将优酷视频的链接地址采集到数据库中,详情看Python抓取优酷视频(上):爬虫使用及数据处理,这里稍微啰嗦几句,采集的其实就是单独视频播放
的页面地址,而不是flash地址,因此不用做地址解析。接下去任务就是搭建一个网站列表页。
思路:
1.采用web.py搭建网站框架,Django太大,web.py上手快。
2.主页面采用列表页,显示title和date
3.采用分页处理,每页10个视频连接
代码:
代码结构:
web_by:
code.py
template:
index.html
code.py
1 import web2 import MySQLdb
3
4 db = web.database(dbn=\'mysql\',user=\'root\',pw=\'root\',db=\'python_test\') #连接数据库
5 render = web.template.render(\'templates/\') #模板路径
6 urls = ( #url设置
7 \'/\',\'index\',
8 \'/page/(\d+)\',\'index\'
9 )
10
11 class index:
12 def GET(self,page=1): #分页函数
13 page = int(page)
14 perpage = 10
15 offset = (page-1)*perpage
16 posts = db.select(\'ykgame\',order="date DESC",offset=offset,
17 limit=perpage)
18 postcount = db.query(\'select count(*) as count from ykgame\')[0]
19 pages = postcount.count / perpage
20 if postcount.count % perpage > 0:
21 pages += 1
22 if page > pages:
23 raise web.seeother(\'/\')
24 else:
25 return render.index(posts=posts,pages=pages)
26
27 if __name__ == "__main__":
28 app = web.application(urls,globals())
29 app.run()
index.html
1 $def with (posts,pages)2 <ul>
3 $for post in posts:
4 <li id= "t$post.id"><a href="$post.href">$post.title</a> $post.date</li>
5 </ul>
6
7 $for page in range(1,pages+1):
8 <a href="/page/$page">$page</a>
代码比较简单就不做分析了,存在的问题是现未按时间顺序排序,原因在于优酷的时间除了日期格式还有比如1小时前等字符,
而采集的时候因为是多线程采集导致没按时间顺序入库。解决办法就是做个时间转换,然后order by date。
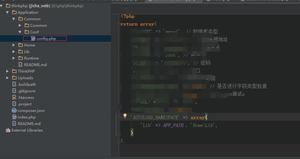
效果:
主页
内容页
以上是 Python抓取优酷视频(下):使用web.py搭建网站框架 的全部内容, 来源链接: utcz.com/z/387882.html