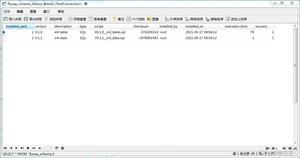
python3 selenium模拟登陆斗鱼提取数据保存数据库

# coding=utf-8
from selenium import webdriver
import json
import time
import pymongo
class Douyu:
def __init__(self):
self.driver = webdriver.Chrome()
# 发送首页请求
self.driver.get("https://www.douyu.com/directory/all")
self.host = \'127.0.0.1\'
self.port = 27017
self.DBname = \'douyu\'
def get_content(self):
time.sleep(3)
li_list = self.driver.find_elements_by_xpath(\'//ul[@id="live-list-contentbox"]/li\')
# print(li_list)
contents = []
# 遍历房间列表
for i in li_list:
item = {}
# 获取房间图片
item[\'img\'] = i.find_element_by_xpath(\'./a//img\').get_attribute("src")
# 获取房间名字
item[\'title\'] = i.find_element_by_xpath(\'./a\').get_attribute("title")
# 获取房间分类
item[\'category\'] = i.find_element_by_xpath(\'./a/div[@class="mes"]/div/span\').text
# 获取主播名字
item[\'name\'] = i.find_element_by_xpath("./a/div[@class=\'mes\']/p/span[1]").text
# 观看人数
item[\'watch_num\'] = i.find_element_by_xpath("./a/div[@class=\'mes\']/p/span[2]").text
# print(item)
contents.append(item)
return contents
# 保存到MongoDB
def save_content(self, contents):
# 创建MongoDB连接
client = pymongo.MongoClient(host=self.host, port=self.port)
# 指向指定的数据库
mdb = client[self.DBname]
self.post = mdb[self.DBname]
self.post.insert(contents)
# 保存到本地
# def save_content(self, contents):
# with open("douyu.json", "a") as f:
# for content in contents:
# json.dump(content, f, ensure_ascii=False, indent=2)
# f.write(\',\n\')
def run(self):
# 1.发送首页请求
# 2.获取首页信息
contents = self.get_content()
# 3.保存内容
self.save_content(contents)
# 4.循环 点击下一页按钮,直到下一页对应的class名字不再是"shark-pager-next"
# 判断有没有下一页
while self.driver.find_element_by_class_name("shark-pager-next"):
# 5.点击下一页按钮
self.driver.find_element_by_class_name("shark-pager-next").click()
# 6.获取下一页的内容
contents = self.get_content()
# 7.保存内容
self.save_content(contents)
if __name__ == \'__main__\':
douyu = Douyu()
douyu.run()
以上是 python3 selenium模拟登陆斗鱼提取数据保存数据库 的全部内容, 来源链接: utcz.com/z/387691.html