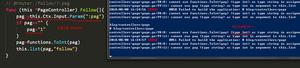
python基本的数据类型

一、python的基本数据类型
int => 整数,主要用来进行数学运算
str ==> 字符串 可以用来保存少量数据并进行相应操作
bool ==> 判断真假,True,False
list ==> 存储大量数据,用[]表示
tuple ==> 元祖,不可发生改变,用()表示
dict ==> 字典,保存键值对,一样可以保存大量数据
set ==> 集合,保存大量数据,不可以重复其实就是不保存 value 的dict
二、整数
在python3中所有的证书都是int类型,在python2 中如果数据量比较大,会使用long类型
在python3中不存在long类型
整数可以进行的操作:
bit_length(),计算整数在内存中占用的二进制码的长度
三、布尔值(bool)
取值只有True和False。bool值没有操作
转换问题:
str ==> int int(str)
int ==> str str(int)
int ==> bool bool(int)
bool ==> int int(bool)
str ==> bool bool(str)
bool ==> str(bool)
四、字符串
把字符连成串,在python中用', ", ''', """引起来的内容被称为字符串
4·1 切片和索引
1.索引。索引就是下标。下标从0开始
1 # 0123456 7 82 s1 = "python最⽜牛B"
3 print(s1[0]) # 获取第0个
4 print(s1[1])
5 print(s1[2])
6 print(s1[3])
7 print(s1[4])
8 print(s1[5])
9 print(s1[6])
10 print(s1[7])
11 print(s1[8])
12 # print(s1[9]) # 没有9, 越界了. 会报错
13 print(s1[-1]) # -1 表示倒数.
14 print(s1[-2]) # 倒数第二个
2.切片,我们可以使用下标来街区部分字符串的内容
语法: str[start: end]
规则: 顾头不顾腚, 从start开始截取. 截取到end位置. 但不包括end
1 s2 = "python最牛B"2 8 1000 4
3 print(s2[0:3]) # 从0获取到3. 不不包含3. 结果: pyt
4 print(s2[6:8]) # 结果 最牛
5 print(s2[6:9]) # 最⼤大是8. 但根据顾头不顾腚, 想要取到8必须给9
6 print(s2[6:10]) # 如果右边已经过了最大值. 相当于获取到最后
7 print(s2[4:]) # 如果想获取到最后. 那么最后一个值可以不给.
8 print(s2[-1:-5]) # 从-1 获取到 -5 这样是获取不不到任何结果的. 从-1向右数. 你怎么数
9 也数不不到-5
10 print(s2[-5:-1]) # 牛b, 取到数据了. 但是. 顾头不不顾腚. 怎么取最后一个呢?
11 print(s2[-5:]) # 什什么都不写就是最后了
12 print(s2[:-1]) # 这个是取到倒数第一个
13 print(s2[:]) # 原样输出
跳着截取
1 # 跳着取, 步长2 print(s2[1:5:2]) # 从第一个开始取, 取到第5个,每2个取1个, 结果: yh, 分析: 1:5=>
3 ytho => yh
4 print(s2[:5:2]) # 从头开始到第五个. 每两个取一个
5 print(s2[4::2]) # 从4开始取到最后. 每两个取一个
6 print(s2[-5::2]) # 从-5取到最后.每两个取一个
7 print(s2[-1:-5]) # -1:-5什什么都没有. 因为是从左往右获取的.
8 print(s2[-1:-5:-1]) # 步⻓长是-1. 这时就从右往左取值了了
9 print(s2[-5::-3]) # 从倒数第5个开始. 到最开始. 每3个取一个, 结果oy
步长: 如果是整数, 则从左往右取. 如果是负数. 则从右往左取. 默认是1
切片语法:
str[start:end:step]
start: 起始位置
end: 结束位置
step:步长
4.2 字符串的相关操作方法
切记, 字符串串是不可变的对象, 所以任何操作对原字符串是不会有任何影响的
1.字符串的大小写转换
1 s1.capitalize()2 print(s1) # 输出发现并没有任何的变化. 因为这里的字符串本身是不会发生改变的. 需要我们
3 重新获取
4 ret1 = s1.capitalize()
5 print(ret1)
6 # 大小写的转换
7 ret = s1.lower() # 全部转换成小写
8 print(ret)
9 ret = s1.upper() # 全部转换成大写
10 print(ret)
11 # 应用, 校验⽤用户输入的验证码是否合法
12 verify_code = "abDe"
13 user_verify_code = input("请输入验证码:")
14 if verify_code.upper() == user_verify_code.upper():
15 print("验证成功")
16 else:
17 print("验证失败")
18 ret = s1.swapcase() # 大小写互相转换
19 print(ret)
20 # 不不常⽤用
21 ret = s1.casefold() # 转换成小写, 和lower的区别: lower()对某些字符支持不够好.
22 casefold()对所有字母都有效. ⽐比如东欧的一些字母
23 print(ret)
24 s2 = "БBß" # 俄美德
25 print(s2)
26 print(s2.lower())
27 print(s2.casefold())
28 # 每个被特殊字符隔开的字母⾸首字母大写
29 s3 = "alex eggon,taibai*yinwang_麻花藤"
30 ret = s3.title() # Alex Eggon,Taibai*Yinwang_麻花藤
31 print(ret)
32 # 中文也算是特殊字符
33 s4 = "alex⽼老老男孩wusir" # Alex⽼老男孩Wusir
34 print(s4.title())
2.切来切去
1 # 居中2 s5 = "周杰伦"
3 ret = s5.center(10, "*") # 拉长成10, 把原字符串放中间.其余位置补*
4 print(ret)
5 # 更改tab的长度
6 s6 = "alex wusir\teggon"
7 print(s6)
8 print(s6.expandtabs()) # 可以改变\t的长度, 默认长度更更改为8
9 # 去空格
10 s7 = " alex wusir haha "
11 ret = s7.strip() # 去掉左右两端的空格
12 print(ret)
13 ret = s7.lstrip() # 去掉左边空格
14 print(ret)
15 ret = s7.rstrip() # 去掉右边空格
16 print(ret)
17 # 应⽤用, 模拟用户登录. 忽略略⽤用户输入的空格
18 username = input("请输⼊入⽤用户名:").strip()
19 password = input("请输⼊入密码: ").strip()
20 if username == 'alex' and password == '123':
21 print("登录成功")
22 else:
23 print("登录失败")
24 s7 = "abcdefgabc"
25 print(s7.strip("abc")) # defg 也可以指定去掉的元素,
26 # 字符串串替换
27 s8 = "sylar_alex_taibai_wusir_eggon"
28 ret = s8.replace('alex', '⾦金金⻆角⼤大王') # 把alex替换成金角⼤大王
29 print(s8) # sylar_alex_taibai_wusir_eggon 切记, 字符串串是不可变对象. 所有操作都
30 是产⽣生新字符串返回
31 print(ret) # sylar_金角⼤大王_taibai_wusir_eggon
32 ret = s8.replace('i', 'SB', 2) # 把i替换成SB, 替换2个
33 print(ret) # sylar_alex_taSBbaSB_wusir_eggon
34 # 字符串切割
35 s9 = "alex,wusir,sylar,taibai,eggon"
36 lst = s9.split(",") # 字符串串切割, 根据,进行切割
37 print(lst)
38 s10 = """诗⼈人
39 学者
40 感叹号
41 渣渣"""
42 print(s10.split("\n")) # ⽤用\n切割
43 # 坑
44 s11 = "银王哈哈银王呵呵银王吼吼银王"
45 lst = s11.split("银王") # ['', '哈哈', '呵呵', '吼吼', ''] 如果切割符在左右两端. 那么一
46 定会出现空字符串串.深坑请留留意
47 print(lst)
3. 格式化输出
1 # 格式化输出2 s12 = "我叫%s, 今年年d岁了, 我喜欢%s" % ('sylar', 18, '周杰伦') # 之前的写法
3 print(s12)
4 s12 = "我叫{}, 今年年{}岁了, 我喜欢{}".format("周杰伦", 28, "周润发") # 按位置格式化
5 print(s12)
6 s12 = "我叫{0}, 今年{2}岁了, 我喜欢{1}".format("周杰伦", "周润发", 28) # 指定位置
7 print(s12)
8 s12 = "我叫{name}, 今年年{age}岁了, 我喜欢{singer}".format(name="周杰伦", singer="周润
9 发", age=28) # 指定关键字
10 print(s12)
4.查找
1 s13 = "我叫sylar, 我喜欢python, java, c等编程语言."2 ret1 = s13.startswith("sylar") # 判断是否以sylar开头
3 print(ret1)
4 ret2 = s13.startswith("我叫sylar") # 判断是否以我叫sylar开头
5 print(ret2)
6 ret3 = s13.endswith("语⾔") # 是否以'语⾔'结尾
7 print(ret3)
8 ret4 = s13.endswith("语⾔.") # 是否以'语⾔.'结尾
9 print(ret4)
10 ret7 = s13.count("a") # 查找"a"出现的次数
11 print(ret7)
12 ret5 = s13.find("sylar") # 查找'sylar'出现的位置
13 print(ret5)
14 ret6 = s13.find("tory") # 查找'tory'的位置, 如果没有返回-1
15 print(ret6)
16 ret7 = s13.find("a", 8, 22) # 切⽚找
17 print(ret7)
18 ret8 = s13.index("sylar") # 求索引位置. 注意. 如果找不到索引. 程序会报错
19 print(ret8)
5. 条件判断
1 # 条件判断2 s14 = "123.16"
3 s15 = "abc"
4 s16 = "_abc!@"
5 # 是否由字母和数字组成
6 print(s14.isalnum())
7 print(s15.isalnum())
8 print(s16.isalnum())
9 # 是否由字母组成
10 print(s14.isalpha())
11 print(s15.isalpha())
12 print(s16.isalpha())
13 # 是否由数字组成, 不包括小数点
14 print(s14.isdigit())
15 print(s14.isdecimal())
16 print(s14.isnumeric()) # 这个比较牛B. 中文都识别.
17 print(s15.isdigit())
18 print(s16.isdigit())
19 # 练习. 用算法判断某⼀个字符串是否是⼩小数
20 s17 = "-123.12"
21 s17 = s17.replace("-", "") # 替换掉负号
22 if s17.isdigit():
23 print("是整数")
24 else:
25 if s17.count(".") == 1 and not s17.startswith(".") and not s17.endswith("."):
26 print("是⼩小数")
27 else:
28 print("不不是⼩小数")
6. 计算字符串的长度
1 s18 = "我是你的眼, 我也是a"2 ret = len(s18) # 计算字符串的长度
3 print(ret)
注意: len()是python的内置函数. 所以访问方式也不一样. 你就记着len()和print()一样就行
了
7. 迭代
我们可以使用for循环来便利(获取)字符串中的每一个字符
语法:
for 变量 in 可迭代对象:
pass
可迭代对象: 可以一个一个往外取值的对象
1 s19 = "大家好, 我是VUE, 前端的小朋友们. 你们好么?"2 # 用while循环
3 index = 0
4 while index < len(s19):
5 print(s19[index]) # 利用索引切片来完成字符的查找
6 index = index + 1
7 # for循环, 把s19中的每一个字符拿出来赋值给前面的c
8 for c in s19:
9 print(c)
10 '''
11 in有两种用法:
12 1. 在for中. 是把每一个元素获取到赋值给前面的变量.
13 2. 不在for中. 判断xxx是否出现在str中.
14 '''
15 print('VUE' in s19)
16 # 练习, 计算在字符串"I am sylar, I'm 14 years old, I have 2 dogs!"
17 s20 = "I am sylar, I'm 14 years old, I have 2 dogs!"
18 count = 0
19 for c in s20:
20 if c.isdigit():
21 count = count + 1
22 print(count)
以上是 python基本的数据类型 的全部内容, 来源链接: utcz.com/z/386906.html