正则表达式匹配不包含某些字符串的技巧
经常我们会遇到想找出不包含某个字符串的文本,程序员最容易想到的是在正则表达式里使用,^(hede)来过滤”hede”字串,但这种写法是错误的。我们可以这样写:[^hede],但这样的正则表达式完全是另外一个意思,它的意思是字符串里不能包含‘h',‘e',‘d'三个但字符。那什么样的正则表达式能过滤出不包含完整“hello”字串的信息呢?
事实上,说正则表达式里不支持逆向匹配并不是百分之百的正确。就像这个问题,我们就可以使用否定式查找来模拟出逆向匹配,从而解决我们的问题:
^((?!hede).)*$
上面这个表达式就能过滤出不包含‘hede'字串的信息。我上面也说了,这种写法并不是正则表达式“擅长”的用法,但它是可以这样用的。
解释
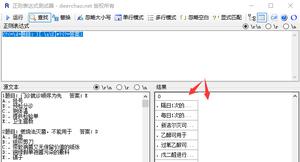
一个字符串是由n个字符组成的。在每个字符之前和之后,都有一个空字符。这样,一个由n个字符组成的字符串就有n+1个空字符串。我们来看一下“ABhedeCD”这个字符串:
所有的e编号的位置都是空字符。表达式(?!hede).会往前查找,看看前面是不是没有“hede”字串,如果没有(是其它字符),那么.(点号)就会匹配这些其它字符。这种正则表达式的“查找”也叫做“zero-width-assertions”(零宽度断言),因为它不会捕获任何的字符,只是判断。
在上面的例子里,每个空字符都会检查其前面的字符串是否不是‘hede',如果不是,这.(点号)就是匹配捕捉这个字符。表达式(?!hede).只执行一次,所以,我们将这个表达式用括号包裹成组(group),然后用*(星号)修饰——匹配0次或多次:
((?!hede).)*。
你可以理解,正则表达式((?!hede).)*匹配字符串"ABhedeCD"的结果false,因为在e3位置,(?!hede)匹配不合格,它之前有"hede"字符串,也就是包含了指定的字符串。
在正则表达式里, ?! 是否定式向前查找,它帮我们解决了字符串“不包含”匹配的问题。
以下是一些补充:
分享下php生成随机数的三种方法,生成1-10之间的不重复随机数,php生成不重复随机数的例子,需要的朋友参考下。
在hacker news上看到regex golf,几道很有趣的正则表达式的题,有的需要用到不匹配这种匹配,比如需要匹配不包含某个单词的串。
开始正题之前,先来看看正则表达式的语法:
[abc] a或b或c . 任意单个字符 a? 零个或一个a
[^abc] 任意不是abc的字符 \s 空格 a* 零个或多个a
[a-z] a-z的任意字符 \S 非空格 a+ 一个或多个a
[a-zA-Z] a-z或A-Z \d 任意数字 a{n} 正好出现n次a
^ 一行开头 \D 任意非数字 a{n,} 至少出现n次a
$ 一行末尾 \w 任意字母数字或下划线 a{n,m} 出现n-m次a
(...) 括号用于分组 \W 任意非字母数字或下划线 a*? 零个或多个a(非贪婪)
(a|b) a或b \b 单词边界 (a)...\1 引用分组
(?=a) 前面有a (?!a) 前面没有a \B 非单词边界
正则表达式中有(?=a)和(?!a)来表示我们是否需要匹配某个东西。
所以,有需要不匹配某样内容时,就可以用(?!a)了。比如要匹配不含hello的字符串就可以这样写。
^(?!.*hello)
这里.*用来表示hello之前可能有其他的字符,为什么还要加^呢,因为如果不加的话,可能匹配到h之后的这个位置上了。
现在就可以解决regex golf上的abba这道题了。
这道题是去匹配不含abba这种形式的单词,比如abba,anallagmatic就不应该匹配上。
正则表达式代码:
^(?!.*(.)(.)\2\1)
然后利用不匹配,还可以解决prime这道题,这道题匹配有素数个x的串,先看正则。
^(?!(xx+)\1+$)
(xx+)是匹配2个及2个以上的x,(xx+)\1+就是匹配重复出现2个及以上的串,所以(xx+)\1+就表示了那些非素数的串,那么素数串就是除去这些非素数串,即是以上的正则表达式了。
PS:关于正则,本站还提供了2款非常简便实用的正则测试工具供大家使用:
JavaScript正则表达式在线测试工具:
http://tools.jb51.net/regex/javascript
正则表达式在线生成工具:
http://tools.jb51.net/regex/create_reg
以上是 正则表达式匹配不包含某些字符串的技巧 的全部内容, 来源链接: utcz.com/z/361995.html
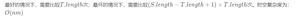
![正则表达式中 [\s\S]* 什么意思 居然能匹配所有字符 [] 不是范围描述符吗?](/wp-content/uploads/thumbs/270159_thumbnail.jpg)