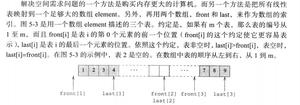
什么是数据分类?
分类是一种数据挖掘方法,用于预测数据实例的团队成员资格。这是一个两步程序。第一步,建立一个模型,定义一组预定的数据类或方法。该模型是通过考虑由属性定义的数据库元组开发的。
每个元组都被认为属于一个预定义的类,由属性之一决定,称为类标签属性。在分类框架中,数据元组也被定义为样本、例子或对象。分析以开发模型的数据元组共同形成训练数据集。创建训练集的单个元组被定义为训练样本,并从样本总体中随意选择。
因为支持每个训练样本的类标签,所以这个过程也被称为监督学习。在无监督学习中,训练样本的类标签是匿名的,要学习的多个类可能事先不知道。
学习模型在分类规则、决策树或数值公式的结构中描述。例如,给定用户信用数据的数据库,可以学习分类规则以将用户识别为具有最佳或公平信用评级。这些规则可用于对未来的数据样本进行分类,并支持对数据库内容的良好理解。
保持方法是一种简单的技术,它应用一组类标记样本的测试集。这些样本是随机选择的,独立于训练样本。模型在给定测试集上的效率是受模型适当限制的测试集样本的百分比。对于每个测试样本,著名的类别标签与该样本的学习模型的类别预测是有区别的。
如果模型估计的效率取决于训练数据集,则该估计可能是乐观的,因为学习模型会影响过拟合信息(即,它可能包含了训练信息中不存在的某些特定异常)样本总体)。因此,使用测试集。
学习- 训练信息由分类算法分析。因此,类标签属性是信用评级,并且在分类规则的结构中描述了学习模型或分类器。
分类- 测试数据用于衡量分类规则的效率。如果认为效率可以接受,则可以使用规则来对新数据元组进行分类。
以上是 什么是数据分类? 的全部内容, 来源链接: utcz.com/z/361568.html