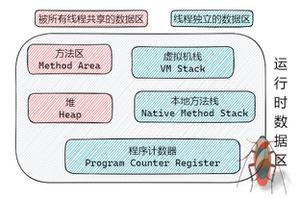
早期数据库模型
数据库模型确定数据库的逻辑结构,并确定可以在哪种基础上以何种方式存储,组织和处理数据。在设计数据库之前,存储数据的唯一方法是在文件存储中,这增加了复杂性,因为程序员不得不花大力气提取数据,并且他们的程序必须执行复杂的解析和关联。
由于Perl具有强大的正则表达式,因此有多种语言(例如Perl)可以更轻松地处理文本。但是,从文件访问数据仍然是一项复杂的任务。由于没有哪个系统更容易出错,开发速度较慢且维护较困难,因此没有标准的数据访问方式。存在数据冗余(不必要地复制数据)和数据完整性差(其中数据在所有位置均未更改,导致提供错误或过时的数据)的问题。
为了解决这些问题,开发了数据库管理系统(DBMS),它提供了一种标准且可靠的方式来访问和更新数据。在应用程序和数据之间存在一个中间层,程序员可以专注于开发应用程序,而不必担心数据访问问题。
因此,我们可以将数据库模型定义为与数据表示方式有关的逻辑模型。数据库设计人员需要更高的概念级别,而不用担心数据的物理存储,从而减少了正在开发应用程序的实际问题与技术实现之间的差距。
数据模型用于组织数据元素并标准化数据元素之间的关系。由于数据元素用于记录现实生活中的人,地点和事物,并且它们之间的事件表示现实,例如,一栋建筑物有很多窗户,或者一只狗有两只眼睛。模型有助于结构化数据,它还定义了一组可以对数据执行的操作。给定的DBMS可以提供多个模型。最佳结构取决于应用程序的数据自然组织以及相关应用程序的要求,其中一些因素是:
交易率(速度),
可靠性,
可维护性
可扩展性
成本。
平(或表)模型是最常规和简单的数据模型,它由一个单一的二维数据元素数组组成,其中给定列的所有成员代表相似的值,而行的所有成员代表与之的关系另一个。例如,列用于名称和密码,它们是系统安全性数据库的一部分。每行包含与特定用户关联的特定密码。该表的列包含定义字符数据,日期或时间信息,整数或浮点数的类型。
现在我们可以说平面文件数据库是一个存储普通非结构化文件(也称为“平面文件”)的数据库。该文件被完全存储在计算机的内存中,因此访问数据结构及其在计算机系统上的操作变得容易。数据库操作完成后,文件将从计算机系统中移出并传输到主机的文件系统中。据说此故事模式是“平坦的”,因为它没有索引结构,并且记录之间通常没有结构关系。
此平面模型最适合小型,简单的数据库。随着数据大小的增长,内存访问变得困难,并且需要更复杂的数据库。姓名,联系电话,地址,手写城市列表是一个平面文件数据库。如果在电子表格中记录了相同的信息,则可以在线使用它来提高搜索功能。也可以使用平面文件数据库模型来传输数据
示例数据库
以下示例说明了平面文件数据库的基本元素。它由组织成表格的一系列列和行组成。
这些列包括姓名(一个人的名字,第二列);团队(此人支持的运动团队的名称,第三列);和数字唯一ID(用于唯一标识记录,第一列)。
对于平面文件数据库,以下类型的数据表示形式是非常标准的-
| ID | 名称 | 球队 |
|---|---|---|
| 101 | 阿比纳夫 | 蓝调 |
| 102 | 阿迪亚 | 蓝调 |
| 103 | 安贾利 | 粉 |
| 104 | 巴夫纳 | 粉 |
| 105 | 夏鲁 | 粉 |
| 106 | 潜水 | 蓝调 |
| 107 | 迪沙 | 粉 |
| 108 | 额山 | 蓝调 |
| 109 | 高里 | 粉 |
以上是 早期数据库模型 的全部内容, 来源链接: utcz.com/z/351486.html