什么是数量减少?
在数量减少中,通过选择替代的、更小的数据表示形式来减少数据量。这些技术可以是参数的或非参数的。对于参数化方法,使用模型来估计数据,因此只需要存储数据参数,而不是实际数据,例如Log-linear模型。非参数方法用于存储数据的简化表示,包括直方图、聚类和采样。
有以下数量减少技术如下 -
回归和对数线性模型- 这些模型可用于近似给定数据。在线性回归中,数据被建模为拟合一条直线。例如,随机变量 y(称为响应变量)可以建模为另一个随机变量 x(称为预测变量)的线性函数,方程为 y = wx+b,其中 y 的方差假设为常数。
对数线性模型- 这些模型用于近似离散多维概率分布。给定一组 n 维元组(例如,由 n 个属性),它可以将每个元组视为 n 维空间中的一个点。
对数线性模型可用于测量多维空间中每个点对于一组离散化属性的概率,这取决于维度组合的较小子集。这使得能够从低维空间生成高维数据字段。
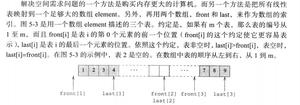
直方图- 直方图使用分箱来近似数据分布,是一种著名的数据缩减形式。属性 A 的直方图将 A 的数据分布划分为不相交的子集或桶。如果每个桶只定义了一个单独的属性值/频率对,则这些桶被称为单例桶。
聚类- 聚类技术将数据元组视为对象。它们将对象划分为组或集群,以便集群内的对象彼此“相似”而与其他集群中的对象“不相似”。它通常根据距离函数根据物体在空间中的“接近”程度来定义。
簇的质量可以通过它的直径来定义,即簇中任意两个对象之间的最大距离。质心距离是集群质量的另一种度量,表示为每个集群对象与集群质心的平均距离,表示“平均对象”或集群区域中的平均点。
采样- 采样可以用作数据缩减方法,因为它可以通过信息的小得多的随机样本(或子集)定义庞大的数据集。
以上是 什么是数量减少? 的全部内容, 来源链接: utcz.com/z/350404.html