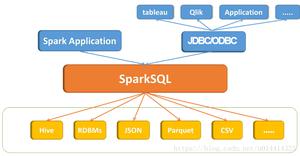
Spark学习笔记之Spark SQL的具体使用
1. Spark SQL是什么?
- 处理结构化数据的一个spark的模块
- 它提供了一个编程抽象叫做DataFrame并且作为分布式SQL查询引擎的作用
2. Spark SQL的特点
- 多语言的接口支持(java python scala)
- 统一的数据访问
- 完全兼容hive
- 支持标准的连接
3. 为什么学习SparkSQL?
我们已经学习了Hive,它是将Hive SQL转换成MapReduce然后提交到集群上执行,大大简化了编写MapReduce的程序的复杂性,由于MapReduce这种计算模型执行效率比较慢。所有Spark SQL的应运而生,它是将Spark SQL转换成RDD,然后提交到集群执行,执行效率非常快!
4. DataFrame(数据框)
- 与RDD类似,DataFrame也是一个分布式数据容器
- 然而DataFrame更像传统数据库的二维表格,除了数据以外,还记录数据的结构信息,即schema
- DataFrame其实就是带有schema信息的RDD
5. SparkSQL1.x的API编程
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
5.1 使用sqlContext创建DataFrame(测试用)
object Ops3 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("Ops3").setMaster("local[3]")
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
val rdd1 = sc.parallelize(List(Person("admin1", 14, "man"),Person("admin2", 16, "man"),Person("admin3", 18, "man")))
val df1: DataFrame = sqlContext.createDataFrame(rdd1)
df1.show(1)
}
}
case class Person(name: String, age: Int, sex: String);
5.2 使用sqlContxet中提供的隐式转换函数(测试用)
import org.apache.spark
val conf = new SparkConf().setAppName("Ops3").setMaster("local[3]")
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
val rdd1 = sc.parallelize(List(Person("admin1", 14, "man"), Person("admin2", 16, "man"), Person("admin3", 18, "man")))
import sqlContext.implicits._
val df1: DataFrame = rdd1.toDF
df1.show()
5.3 使用SqlContext创建DataFrame(常用)
val conf = new SparkConf().setAppName("Ops3").setMaster("local[3]")
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
val linesRDD: RDD[String] = sc.textFile("hdfs://uplooking02:8020/sparktest/")
val schema = StructType(List(StructField("name", StringType), StructField("age", IntegerType), StructField("sex", StringType)))
val rowRDD: RDD[Row] = linesRDD.map(line => {
val lineSplit: Array[String] = line.split(",")
Row(lineSplit(0), lineSplit(1).toInt, lineSplit(2))
})
val rowDF: DataFrame = sqlContext.createDataFrame(rowRDD, schema)
rowDF.show()
6. 使用新版本的2.x的API
val conf = new SparkConf().setAppName("Ops5") setMaster ("local[3]")
val sparkSession: SparkSession = SparkSession.builder().config(conf).getOrCreate()
val sc = sparkSession.sparkContext
val linesRDD: RDD[String] = sc.textFile("hdfs://uplooking02:8020/sparktest/")
//数据清洗
val rowRDD: RDD[Row] = linesRDD.map(line => {
val splits: Array[String] = line.split(",")
Row(splits(0), splits(1).toInt, splits(2))
})
val schema = StructType(List(StructField("name", StringType), StructField("age", IntegerType), StructField("sex", StringType)))
val df: DataFrame = sparkSession.createDataFrame(rowRDD, schema)
df.createOrReplaceTempView("p1")
val df2 = sparkSession.sql("select * from p1")
df2.show()
7. 操作SparkSQL的方式
7.1 使用SQL语句的方式对DataFrame进行操作
val conf = new SparkConf().setAppName("Ops5") setMaster ("local[3]")
val sparkSession: SparkSession = SparkSession.builder().config(conf).getOrCreate()//Spark2.x新的API相当于Spark1.x的SQLContext
val sc = sparkSession.sparkContext
val linesRDD: RDD[String] = sc.textFile("hdfs://uplooking02:8020/sparktest/")
//数据清洗
val rowRDD: RDD[Row] = linesRDD.map(line => {
val splits: Array[String] = line.split(",")
Row(splits(0), splits(1).toInt, splits(2))
})
val schema = StructType(List(StructField("name", StringType), StructField("age", IntegerType), StructField("sex", StringType)))
val df: DataFrame = sparkSession.createDataFrame(rowRDD, schema)
df.createOrReplaceTempView("p1")//这是Sprk2.x新的API 相当于Spark1.x的registTempTable()
val df2 = sparkSession.sql("select * from p1")
df2.show()
7.2 使用DSL语句的方式对DataFrame进行操作
DSL(domain specific language ) 特定领域语言
val conf = new SparkConf().setAppName("Ops5") setMaster ("local[3]")
val sparkSession: SparkSession = SparkSession.builder().config(conf).getOrCreate()
val sc = sparkSession.sparkContext
val linesRDD: RDD[String] = sc.textFile("hdfs://uplooking02:8020/sparktest/")
//数据清洗
val rowRDD: RDD[Row] = linesRDD.map(line => {
val splits: Array[String] = line.split(",")
Row(splits(0), splits(1).toInt, splits(2))
})
val schema = StructType(List(StructField("name", StringType), StructField("age", IntegerType), StructField("sex", StringType)))
val rowDF: DataFrame = sparkSession.createDataFrame(rowRDD, schema)
import sparkSession.implicits._
val df: DataFrame = rowDF.select("name", "age").where("age>10").orderBy($"age".desc)
df.show()
8. SparkSQL的输出
8.1 写出到JSON文件
val conf = new SparkConf().setAppName("Ops5") setMaster ("local[3]")
val sparkSession: SparkSession = SparkSession.builder().config(conf).getOrCreate()
val sc = sparkSession.sparkContext
val linesRDD: RDD[String] = sc.textFile("hdfs://uplooking02:8020/sparktest")
//数据清洗
val rowRDD: RDD[Row] = linesRDD.map(line => {
val splits: Array[String] = line.split(",")
Row(splits(0), splits(1).toInt, splits(2))
})
val schema = StructType(List(StructField("name", StringType), StructField("age", IntegerType), StructField("sex", StringType)))
val rowDF: DataFrame = sparkSession.createDataFrame(rowRDD, schema)
import sparkSession.implicits._
val df: DataFrame = rowDF.select("name", "age").where("age>10").orderBy($"age".desc)
df.write.json("hdfs://uplooking02:8020/sparktest1")
8.2 写出到关系型数据库(mysql)
val conf = new SparkConf().setAppName("Ops5") setMaster ("local[3]")
val sparkSession: SparkSession = SparkSession.builder().config(conf).getOrCreate()
val sc = sparkSession.sparkContext
val linesRDD: RDD[String] = sc.textFile("hdfs://uplooking02:8020/sparktest")
//数据清洗
val rowRDD: RDD[Row] = linesRDD.map(line => {
val splits: Array[String] = line.split(",")
Row(splits(0), splits(1).toInt, splits(2))
})
val schema = StructType(List(StructField("name", StringType), StructField("age", IntegerType), StructField("sex", StringType)))
val rowDF: DataFrame = sparkSession.createDataFrame(rowRDD, schema)
import sparkSession.implicits._
val df: DataFrame = rowDF.select("name", "age").where("age>10").orderBy($"age".desc)
val url = "jdbc:mysql://localhost:3306/test"
//表会自动创建
val tbName = "person1";
val prop = new Properties()
prop.put("user", "root")
prop.put("password", "root")
//SaveMode 默认为ErrorIfExists
df.write.mode(SaveMode.Append).jdbc(url, tbName, prop)
以上是 Spark学习笔记之Spark SQL的具体使用 的全部内容, 来源链接: utcz.com/z/349510.html