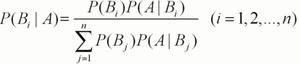为什么朴素贝叶斯分类被称为朴素?
贝叶斯分类器是统计分类器。他们可以预测类成员概率,例如给定样本属于特定类的概率。贝叶斯分类器在应用于大型数据库时也表现出很高的准确性和速度。
一旦定义了类,系统就应该推断出管理分类的规则,因此系统应该能够找到每个类的描述。描述应该只涉及训练集的预测属性,以便只有正例满足描述,而不是负例。如果一个规则的描述涵盖了所有的正例,而没有涵盖一个类的任何一个反例,则称该规则是正确的。
假设所有属性的贡献都是独立的,并且每个属性对分类问题的贡献相等,这是一种称为朴素贝叶斯分类的简单分类方案。通过分析每个“独立”属性的贡献,确定条件概率。通过组合不同属性对要进行的预测的影响来进行分类。
朴素贝叶斯分类被称为朴素,因为它假设类条件独立。属性值对给定类的影响与其他属性的值无关。这个假设是为了减少计算成本,因此被认为是幼稚的。
贝叶斯定理- 让 X 是一个数据元组。在贝叶斯术语中,X 被认为是“证据”。设H为某种假设,例如数据元组X属于指定的C类。确定概率P(H|X)对数据进行分类。这个概率 P (H|X) 是假设 H 在给定“证据”或观察到的数据元组 X 的情况下成立的概率。
P (H|X) 是 H 以 X 为条件的后验概率。例如,假设数据元组的世界仅限于分别由属性年龄和收入描述的客户,并且 X 是具有 Rs 的 30 岁客户。20,000 收入。假设 H 是客户将购买计算机的假设。那么 P (H|X) 反映了在已知客户的年龄和收入的情况下,客户 X 购买计算机的概率。
P (H) 是 H 的先验概率。例如,这是任何给定客户购买计算机的概率,而不管其年龄、收入或任何其他信息。后验概率 P (H|X) 基于比先验概率 P (H) 更多的信息,后者与 X 无关。
类似地,P (X|H) 是 X 以 H 为条件的后验概率。它是客户 X 30 岁并赚取 Rs 的概率。20,000。
P (H)、P (X|H) 和 P (X) 可以从给定的数据中估计出来。贝叶斯定理提供了一种根据 P (H)、P (X|H) 和 计算后验概率 P (H|X) 的方法P(X)。它是由
$$P(H|X)=\frac{P(X|H) P(H)}{ P(X)}$$
以上是 为什么朴素贝叶斯分类被称为朴素? 的全部内容, 来源链接: utcz.com/z/341293.html