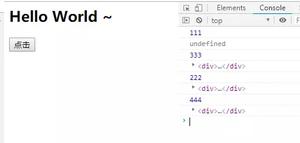
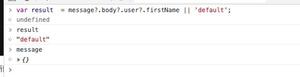
c++中try catch的用法小结
在c++中,可以直接抛出异常之后自己进行捕捉处理,如:(这样就可以在任何自己得到不想要的结果的时候进行中断,比如在进行数据库事务操作的时候,如果某一个语句返回SQL_ERROR则直接抛出异常,在catch块中进行事务回滚(回滚怎么理解?))。
#include <iostream>
#include <exception>
using namespace std;
int main () {
try
{
throw 1;
throw "error";
}
catch(char *str)
{
cout << str << endl;
}
catch(int i)
{
cout << i << endl;
}
}
也可以自己定义异常类来进行处理:
#include <iostream>
#include <exception>
using namespace std;
//可以自己定义Exception
class myexception: public exception
{
virtual const char* what() const throw()
{
return "My exception happened";
}
}myex;
int main () {
try
{
if(true) //如果,则抛出异常;
throw myex;
}
catch (exception& e)
{
cout << e.what() << endl;
}
return 0;
}
同时也可以使用标准异常类进行处理:
#include <iostream>
#include <exception>
using namespace std;
int main () {
try
{
int* myarray= new int[100000];
}
catch (exception& e)
{
cout << "Standard exception: " << e.what() << endl;
}
return 0;
}
一、简单的例子
首先通过一个简单的例子来熟悉C++ 的 try/catch/throw(可根据单步调试来熟悉,try catch throw部分是如何运行的):
#include <stdlib.h>
#include "iostream"
using namespace std;
double fuc(double x, double y) //定义函数
{
if(y==0)
{
throw y; //除数为0,抛出异常
}
return x/y; //否则返回两个数的商
}
int _tmain(int argc, _TCHAR* argv[])
{
double res;
try //定义异常
{
res=fuc(2,3);
cout<<"The result of x/y is : "<<res<<endl;
res=fuc(4,0); //出现异常
}
catch(double) //捕获并处理异常
{
cerr<<"error of dividing zero.\n";
exit(1); //异常退出程序
}
return 0;
}
catch 的数据类型需要与throw出来的数据类型相匹配的。
二、catch(...)的作用
catch(…)能够捕获多种数据类型的异常对象,所以它提供给程序员一种对异常对象更好的控制手段,使开发的软件系统有很好的可靠性。因此一个比较有经验的程序员通常会这样组织编写它的代码模块,如下:
void Func()
{
try
{
// 这里的程序代码完成真正复杂的计算工作,这些代码在执行过程中
// 有可能抛出DataType1、DataType2和DataType3类型的异常对象。
}
catch(DataType1& d1)
{
}
catch(DataType2& d2)
{
}
catch(DataType3& d3)
{
}
/********************************************************* 注意上面try block中可能抛出的DataType1、DataType2和DataType3三
种类型的异常对象在前面都已经有对应的catch block来处理。但为什么
还要在最后再定义一个catch(…) block呢?这就是为了有更好的安全性和
可靠性,避免上面的try block抛出了其它未考虑到的异常对象时导致的程
序出现意外崩溃的严重后果,而且这在用VC开发的系统上更特别有效,因
为catch(…)能捕获系统出现的异常,而系统异常往往令程序员头痛了,现
在系统一般都比较复杂,而且由很多人共同开发,一不小心就会导致一个
指针变量指向了其它非法区域,结果意外灾难不幸发生了。catch(…)为这种
潜在的隐患提供了一种有效的补救措施。 *********************************************************/
catch(…)
{
}
}
三、异常中采用面向对象的处理
首先看下面的例子:
void OpenFile(string f)
{
try
{
// 打开文件的操作,可能抛出FileOpenException
}
catch(FileOpenException& fe)
{
// 处理这个异常,如果这个异常可以很好的得以恢复,那么处理完毕后函数
// 正常返回;否则必须重新抛出这个异常,以供上层的调用函数来能再次处
// 理这个异常对象
int result = ReOpenFile(f);
if (result == false) throw;
}
}
void ReadFile(File f)
{
try
{
// 从文件中读数据,可能抛出FileReadException
}
catch(FileReadException& fe)
{
// 处理这个异常,如果这个异常可以很好的得以恢复,那么处理完毕后函数
// 正常返回;否则必须重新抛出这个异常,以供上层的调用函数来能再次处
// 理这个异常对象
int result = ReReadFile(f);
if (result == false) throw;
}
}
void WriteFile(File f)
{
try
{
// 往文件中写数据,可能抛出FileWriteException
}
catch(FileWriteException& fe)
{
// 处理这个异常,如果这个异常可以很好的得以恢复,那么处理完毕后函数
// 正常返回;否则必须重新抛出这个异常,以供上层的调用函数来能再次处理这个异常对象
int result = ReWriteFile(f);
if (result == false) throw;
}
}
void Func()
{
try
{
// 对文件进行操作,可能出现FileWriteException、FileWriteException
// 和FileWriteException异常
OpenFile(…);
ReadFile(…);
WriteFile(…);
}
// 注意:FileException是FileOpenException、FileReadException和FileWriteException
// 的基类,因此这里定义的catch(FileException& fe)能捕获所有与文件操作失败的异
// 常。
catch(FileException& fe)
{
ExceptionInfo* ef = fe.GetExceptionInfo();
cout << “操作文件时出现了不可恢复的错误,原因是:”<< fe << endl;
}
}
下面是更多面向对象和异常处理结合的例子:
#include <iostream.h>
class ExceptionClass
{
char* name;
public:
ExceptionClass(const char* name="default name")
{
cout<<"Construct "<<name<<endl;
this->name=name;
}
~ExceptionClass()
{
cout<<"Destruct "<<name<<endl;
}
void mythrow()
{
throw ExceptionClass("my throw");
}
}
void main()
{
ExceptionClass e("Test");
try
{
e.mythrow();
}
catch(...)
{
cout<<”*********”<<endl;
}
}
这是输出信息:
Construct Test
Construct my throw
Destruct my throw
****************
Destruct my throw (这里是异常处理空间中对异常类的拷贝的析构)
Destruct Test
======================================
不过一般来说我们可能更习惯于把会产生异常的语句和要throw的异常类分成不同的类来写,下面的代码可以是我们更愿意书写的:
class ExceptionClass
{
public:
ExceptionClass(const char* name="Exception Default Class")
{
cout<<"Exception Class Construct String"<<endl;
}
~ExceptionClass()
{
cout<<"Exception Class Destruct String"<<endl;
}
void ReportError()
{
cout<<"Exception Class:: This is Report Error Message"<<endl;
}
};
class ArguClass
{
char* name;
public:
ArguClass(char* name="default name")
{
cout<<"Construct String::"<<name<<endl;
this->name=name;
}
~ArguClass()
{
cout<<"Destruct String::"<<name<<endl;
}
void mythrow()
{
throw ExceptionClass("my throw");
}
};
_tmain()
{
ArguClass e("haha");
try
{
e.mythrow();
}
catch(int)
{
cout<<"If This is Message display screen, This is a Error!!"<<endl; //这行不会执行
}
catch(ExceptionClass pTest)
{
pTest.ReportError();
}
catch(...)
{
cout<<"***************"<<endl;
}
}
输出Message:
Construct String::haha
Exception Class Construct String
Exception Class Destruct String
Exception Class:: This is Report Error Message
Exception Class Destruct String
Destruct String::haha
四、构造和析构中的异常抛出
先看个程序,假如我在构造函数的地方抛出异常,这个类的析构会被调用吗?可如果不调用,那类里的东西岂不是不能被释放了?
#include <iostream.h>
#include <stdlib.h>
class ExceptionClass1
{
char* s;
public:
ExceptionClass1()
{
cout<<"ExceptionClass1()"<<endl;
s=new char[4];
cout<<"throw a exception"<<endl;
throw 18;
}
~ExceptionClass1()
{
cout<<"~ExceptionClass1()"<<endl;
delete[] s;
}
};
void main()
{
try
{
ExceptionClass1 e;
}
catch(...)
{}
}
结果为:
ExceptionClass1()
throw a exception
在这两句输出之间,我们已经给S分配了内存,但内存没有被释放(因为它是在析构函数中释放的)。应该说这符合实际现象,因为对象没有完整构造。
为了避免这种情况,我想你也许会说:应避免对象通过本身的构造函数涉及到异常抛出。即:既不在构造函数中出现异常抛出,也不应在构造函数调用的一切东西中出现异常抛出。
但是在C++中可以在构造函数中抛出异常,经典的解决方案是使用STL的标准类auto_ptr。
那么,在析构函数中的情况呢?我们已经知道,异常抛出之后,就要调用本身的析构函数,如果这析构函数中还有异常抛出的话,则已存在的异常尚未被捕获,会导致异常捕捉不到。
五、标准C++异常类
标准异常都派生自一个公共的基类exception。基类包含必要的多态性函数提供异常描述,可以被重载。下面是exception类的原型:
class exception
{
public:
exception() throw();
exception(const exception& rhs) throw();
exception& operator=(const exception& rhs) throw();
virtual ~exception() throw();
virtual const char *what() const throw();
};
C++有很多的标准异常类:
namespace std
{
//exception派生
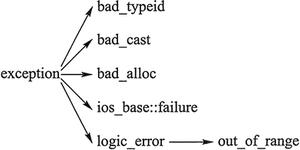
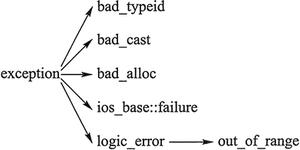
class logic_error; //逻辑错误,在程序运行前可以检测出来
//logic_error派生
class domain_error; //违反了前置条件
class invalid_argument; //指出函数的一个无效参数
class length_error; //指出有一个超过类型size_t的最大可表现值长度的对象的企图
class out_of_range; //参数越界
class bad_cast; //在运行时类型识别中有一个无效的dynamic_cast表达式
class bad_typeid; //报告在表达试typeid(*p)中有一个空指针p
//exception派生
class runtime_error; //运行时错误,仅在程序运行中检测到
//runtime_error派生
class range_error; //违反后置条件
class overflow_error; //报告一个算术溢出
class bad_alloc; //存储分配错误
}
标准库异常类定义在以下四个头文件中
1、exception头文件:定义了最常见的标准异常类,其类名为exception。只通知异常的产生,但不会提供更多的信息
2、stdexcept头文件定义了以下几种常见异常类
函数 功能或作用
exception 最常见的问题
runtime_error 运行时错误:仅在运行时才能检测到的问题
range_error 运行时错误:生成的结果超出了有意义的值域范围
overflow_error 运行时错误:计算上溢
underflow_error 运行时错误:计算下溢
logic_error 逻辑错误:可在运行前检测到的问题
domain_error 逻辑错误:参数的结果值不存在
invalid_argument 逻辑错误:不合适的参数
length_error 逻辑错误:试图生成一个超出该类型最大长度的对象
out_of_range 逻辑错误:使用一个超出有效范围的值
3、new头文件定义了bad_alloc异常类型,提供因无法分配内存而由new抛出的异常
4、type_info头文件定义了bad_cast异常类型(要使用type_info必须包含typeinfo头文件)
下面是使用异常类的例子:
首先,我定义了几个异常类,这些类也可以从标准异常类进行派生,如下
class BadInitializers
{
public:
BadInitializers() {}
};
class OutOfBounds
{
public:
OutOfBounds(int i) { cout<<"Size "<<i<<" is illegal!!!"<<endl; }
};
class SizeMismatch
{
public:
SizeMismatch() {}
};
然后要在程序中需要的地方使用throw来抛出异常类,两个抛出异常类的例子如下
template <class T>
Array1D<T>::Array1D(int sz)
{
if(sz<0)
{
//throw BadInitializers();
throw invalid_argument("Size has to be bigger than 0!!!");
}
size=sz;
element=new T[size];
}
template <class T>
T &Array1D<T>::operator[](int i) const
{
if(i<0||i>=size)
{
throw OutOfBounds(i);
}
return element[i];
}
然后在主程序中使用try...catch...来捕获异常,并进行相应的处理,如下
try
{
int i=0;
Array1D<int> a1(5);
a1[0]=1;
a1[1]=3;
a1[2]=5;
a1[3]=7;
a1[4]=8;
Array1D<int> a2(a1);
for(i=0;i<a2.Size();i++)
{
cout<<a2[i]<<" ";
}
cout<<endl;
Array1D<int> a3(5);
a3=a1+a2;
cout<<a3;
}
catch(BadInitializers)
{
cout<<"Error:BadInitializers!!!"<<endl;
}
catch(OutOfBounds &e)
{
cout<<"Error:OutOfBounds!!!"<<endl;
}
catch(SizeMismatch &e)
{
cout<<"Error:SizeMismatch!!!"<<endl;
}
catch(invalid_argument &e)
{
cout<<"Error:"<<e.what()<<endl;
}
catch(...)
{
cout<<"An unknown error!!!"<<endl;
}
六、try finally使用
__try
{
file://保护块
}
__finally
{
file://结束处理程序
}
在上面的代码段中,操作系统和编译程序共同来确保结束处理程序中的__f i n a l l y代码块能够被执行,不管保护体(t r y块)是如何退出的。不论你在保护体中使用r e t u r n,还是g o t o,或者是longjump,结束处理程序(f i n a l l y块)都将被调用。
我们来看一个实列:(返回值:10, 没有Leak,性能消耗:小)
DWORD Func_SEHTerminateHandle()
{
DWORD dwReturnData = 0;
HANDLE hSem = NULL;
const char* lpSemName = "TermSem";
hSem = CreateSemaphore(NULL, 1, 1, lpSemName);
__try
{
WaitForSingleObject(hSem,INFINITE);
dwReturnData = 5;
}
__finally
{
ReleaseSemaphore(hSem,1,NULL);
CloseHandle(hSem);
}
dwReturnData += 5;
return dwReturnData;
}
这段代码应该只是做为一个基础函数,我们将在后面修改它,来看看结束处理程序的作用:
====================
在代码加一句:(返回值:5, 没有Leak,性能消耗:中下)
DWORD Func_SEHTerminateHandle()
{
DWORD dwReturnData = 0;
HANDLE hSem = NULL;
const char* lpSemName = "TermSem";
hSem = CreateSemaphore(NULL, 1, 1, lpSemName);
__try
{
WaitForSingleObject(hSem,INFINITE);
dwReturnData = 5;
return dwReturnData;
}
__finally
{
ReleaseSemaphore(hSem,1,NULL);
CloseHandle(hSem);
}
dwReturnData += 5;
return dwReturnData;
}
在try块的末尾增加了一个return语句。这个return语句告诉编译程序在这里要退出这个函数并返回dwTemp变量的内容,现在这个变量的值是5。但是,如果这个return语句被执行,该线程将不会释放信标,其他线程也就不能再获得对信标的控制。可以想象,这样的执行次序会产生很大的问题,那些等待信标的线程可能永远不会恢复执行。
通过使用结束处理程序,可以避免return语句的过早执行。当return语句试图退出try块时,编译程序要确保finally块中的代码首先被执行。要保证finally块中的代码在try块中的return语句退出之前执行。在程序中,将ReleaseSemaphore的调用放在结束处理程序块中,保证信标总会被释放。这样就不会造成一个线程一直占有信标,否则将意味着所有其他等待信标的线程永远不会被分配CPU时间。
在finally块中的代码执行之后,函数实际上就返回。任何出现在finally块之下的代码将不再执行,因为函数已在try块中返回。所以这个函数的返回值是5,而不是10。
读者可能要问编译程序是如何保证在try块可以退出之前执行finally块的。当编译程序检查源代码时,它看到在try块中有return语句。这样,编译程序就生成代码将返回值(本例中是5)保存在一个编译程序建立的临时变量中。编译程序然后再生成代码来执行f i n a l l y块中包含的指令,这称为局部展开。更特殊的情况是,由于try块中存在过早退出的代码,从而产生局部展开,导致系统执行finally块中的内容。在finally块中的指令执行之后,编译程序临时变量的值被取出并从函数中返回。
可以看到,要完成这些事情,编译程序必须生成附加的代码,系统要执行额外的工作。
finally块的总结性说明
我们已经明确区分了强制执行finally块的两种情况:
• 从try块进入finally块的正常控制流。
• 局部展开:从try块的过早退出(goto、long jump、continue、break、return等)强制控制转移到finally块。
第三种情况,全局展开( global unwind),这个以后再看。
七、C++异常参数传递
从语法上看,在函数里声明参数与在catch子句中声明参数是一样的,catch里的参数可以是值类型,引用类型,指针类型。例如:
try
{
.....
}
catch(A a)
{
}
catch(B& b)
{
}
catch(C* c)
{
}
尽管表面是它们是一样的,但是编译器对二者的处理却又很大的不同。调用函数时,程序的控制权最终还会返回到函数的调用处,但是抛出一个异常时,控制权永远不会回到抛出异常的地方。
class A;
void func_throw()
{
A a;
throw a; //抛出的是a的拷贝,拷贝到一个临时对象里
}
try
{
func_throw();
}
catch(A a) //临时对象的拷贝
{
}
当我们抛出一个异常对象时,抛出的是这个异常对象的拷贝。当异常对象被拷贝时,拷贝操作是由对象的拷贝构造函数完成的。该拷贝构造函数是对象的静态类型(static type)所对应类的拷贝构造函数,而不是对象的动态类型(dynamic type)对应类的拷贝构造函数。此时对象会丢失RTTI信息。
异常是其它对象的拷贝,这个事实影响到你如何在catch块中再抛出一个异常。比如下面这两个catch块,乍一看好像一样:
catch (A& w) // 捕获异常
{
// 处理异常
throw; // 重新抛出异常,让它继续传递
}
catch (A& w) // 捕获Widget异常
{
// 处理异常
throw w; // 传递被捕获异常的拷贝
}
第一个块中重新抛出的是当前异常(current exception),无论它是什么类型。(有可能是A的派生类)
第二个catch块重新抛出的是新异常,失去了原来的类型信息。
一般来说,你应该用throw来重新抛出当前的异常,因为这样不会改变被传递出去的异常类型,而且更有效率,因为不用生成一个新拷贝。
看看以下这三种声明:
catch (A w) ... // 通过传值
catch (A& w) ... // 通过传递引用,一个被异常抛出的对象(总是一个临时对象)可以通过普通的引用捕获
catch (const A& w) ... //const引用
catch (A w) ... // 通过传值捕获
会建立两个被抛出对象的拷贝,一个是所有异常都必须建立的临时对象,第二个是把临时对象拷贝进w中。实际上,编译器会优化掉一个拷贝。同样,当我们通过引用捕获异常时,
catch (A& w) ... // 通过引用捕获
catch (const A& w) ... //const引用捕获
这仍旧会建立一个被抛出对象的拷贝:拷贝是一个临时对象。相反当我们通过引用传递函数参数时,没有进行对象拷贝。话虽如此,但是不是所有编译器都如此。
通过指针抛出异常与通过指针传递参数是相同的。不论哪种方法都是一个指针的拷贝被传递。你不能认为抛出的指针是一个指向局部对象的指针,因为当异常离开局部变量的生存空间时,该局部变量已经被释放。Catch子句将获得一个指向已经不存在的对象的指针。这种行为在设计时应该予以避免。
另外一个重要的差异是在函数调用者或抛出异常者与被调用者或异常捕获者之间的类型匹配的过程不同。在函数传递参数时,如果参数不匹配,那么编译器会尝试一个类型转换,如果存在的话。而对于异常处理的话,则完全不是这样。见一下的例子:
void func_throw()
{
CString a;
throw a; //抛出的是a的拷贝,拷贝到一个临时对象里
}
try
{
func_throw();
}
catch(const char* s)
{
}
尽管如此,在catch子句中进行异常匹配时可以进行两种类型转换。第一种是基类与派生类的转换,一个用来捕获基类的catch子句也可以处理派生类类型的异常。反过来,用来捕获派生类的无法捕获基类的异常。
第二种是允许从一个类型化指针(typed pointer)转变成无类型指针(untyped pointer),所以带有const void* 指针的catch子句能捕获任何类型的指针类型异常:
catch (const void*) ... //可以捕获所有指针异常
另外,你还可以用catch(...)来捕获所有异常,注意是三个点。
传递参数和传递异常间最后一点差别是catch子句匹配顺序总是取决于它们在程序中出现的顺序。因此一个派生类异常可能被处理其基类异常的catch子句捕获,这叫异常截获,一般的编译器会有警告。
class A {
public:
A()
{
cout << "class A creates" << endl;
}
void print()
{
cout << "A" << endl;
}
~A()
{
cout << "class A destruct" << endl;
}
};
class B: public A
{
public:
B()
{
cout << "class B create" << endl;
}
void print()
{
cout << "B" << endl;
}
~B()
{
cout << "class B destruct" << endl;
}
};
void func()
{
B b;
throw b;
}
try
{
func();
}
catch( B& b) //必须将B放前面,如果把A放前面,B放后面,那么B类型的异常会先被截获。
{
b.print();
}
catch (A& a)
{
a.print() ;
}
这篇文章就介绍到这了,需要的朋友可以参考一下。
以上是 c++中try catch的用法小结 的全部内容, 来源链接: utcz.com/z/336793.html