什么是信息检索?
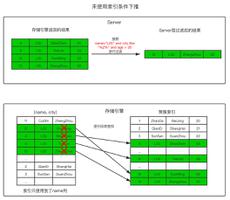
信息检索 (IR) 是一个与数据库系统并行发展多年的领域。与数据库系统领域针对结构化数据的查询和事务处理不同,信息检索关注的是从多个基于文本的文档中组织和检索数据。
由于信息检索和数据库系统各自处理不同类型的数据,因此信息检索系统通常不存在一些数据库系统问题,例如并发控制、恢复、事务管理和更新。存在一些传统数据库系统通常不会遇到的常见信息检索问题,例如非结构化文档、基于关键字的近似搜索以及相关性的概念。
由于文本数据的丰富性,信息检索已经发现了多种应用。存在多种信息检索系统,包括在线图书馆目录系统、在线记录管理系统以及当前开发的更多网络搜索引擎。
一般的数据检索问题是根据用户的查询在文档集中定位相关文档,这通常是定义信息需求的一些关键字,尽管它也可以是相关记录的示例。
当用户有一些临时(即短期)数据需求时,这最合适,包括寻找购买二手车的数据。当用户有长期的数据需求(例如研究人员的兴趣)时,如果判断新到达的数据元素与用户的数据相关,检索系统也可以主动向用户“推送”该元素需要。
评估文本检索质量有两种基本措施,如下所示 -
Precision - 这是实际与查询相关的检索数据的百分比(即“正确”响应)。它正式表示为
$$precision=\frac{|\left\{ 相关\right\}\cap\left\{ 检索到\right\}|}{|\left\{ 检索到\right\}|}$$
Recall - 这是与查询相关并实际检索到的记录的百分比。它正式表示为
$$recall=\frac{|\left\{ 相关\right\}\cap\left\{ 检索到\right\}|}{|\left\{ 相关\right\}|}$$
信息检索系统通常需要在召回率和精度之间进行权衡,反之亦然。一种常用的权衡是 F 分数,它表示为召回率和精度的调和平均值 -
$$F\underline{}score=\frac{recall \times precision }{(recall+precision)^{2}}$$
谐波意味着太麻烦一个系统,它为另一个牺牲一个措施。准确率、召回率和 F 分数是检索记录集合的基本度量。这三个度量对于比较两个排序的文件列表通常没有用,因为它们对检索集中的文档的内部排序不敏感。
以上是 什么是信息检索? 的全部内容, 来源链接: utcz.com/z/335460.html