JavaWeb中文编码问题实例讲解
一、JavaWeb编程中乱码的成因
因为计算机只认识0与1,在网络上要想传输各种字符就需要进行编码。而由于编码、传输、解码过程存在各种不确定性,导致乱码问题频发,成为困扰初学者的一大问题。本文就试图用最简单的示例解释乱码问题。
1.为什么会出现乱码问题
如同发电报一样,如果发报的采用一个密码本进行发报,而接收端采用另外的密码本进行解码,肯定会导致无法解码一样。如果在计算机网络中传输数据,发送端采用的编码和接收端采用的编码不一致就会导致乱码问题。
2.认识各种编码:
ASCII:
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。它是现今最通用的单字节编码系统,并等同于国际标准ISO/IEC 646。
ISO-8859-1:
由于ASCII是美国标准,其收录了空格及94个“可印刷字符”,足以给英语使用。但是,其他使用拉丁字母的语言(主要是欧洲国家的语言),都有一定数量的附加符号字母,故需要使用ASCII及控制字符以外的区域来储存及表示。
为了解决这个问题,国际标准化组织(ISO)及国际电工委员会(IEC)联合制定的一系列8位字符集的标准ISO-8859,其全称ISO/IEC 8859,现时定义了15个字符集。除了使用拉丁字母的语言外,使用西里尔字母的东欧语言、希腊语、泰语、现代阿拉伯语、希伯来语等,都可以使用这个形式来储存及表示。
GBK/GB2312:
为了解决中文的显示和编辑问题,1980年中国国家标准总局发布了GB2312标准,全称是《信息交换用汉字编码字符集》,标准号是GB 2312—1980。GB2312编码适用于汉字处理、汉字通信等系统之间的信息交换,通行于中国大陆;新加坡等地也采用此编码。中国大陆几乎所有的中文系统和国际化的软件都支持GB 2312。基本集共收入汉字6763个和非汉字图形字符682个。GB 2312的出现,基本满足了汉字的计算机处理需要,它所收录的汉字已经覆盖中国大陆99.75%的使用频率。但是对于人名、古汉语等方面出现的罕用字,GB 2312不能处理,这导致了后来GBK及GB 18030汉字字符集的出现。
1995年中国国家标准总局又颁布了《汉字编码扩展规范》(GBK)。GBK与GB 2312—1980国家标准所对应的内码标准兼容,同时在字汇一级支持ISO/IEC10646—1和GB 13000—1的全部中、日、韩(CJK)汉字,共计20902字。
国家标准GB18030-2005《信息技术 中文编码字符集》是我国继GB2312-1980和GB13000.1-1993之后最重要的汉字编码标准,是我国计算机系统必须遵循的基础性标准之一。 GB18030有两个版本:GB18030-2000和GB18030-2005。GB18030-2000是GBK的取代版本,它的主要特点是在GBK基础上增加了CJK统一汉字扩充A的汉字。GB18030-2005的主要特点是在GB18030-2000基础上增加了CJK统一汉字扩充B的汉字。GB18030-2005是我国自主研制的以汉字为主并包含多种我国少数民族文字(如藏、蒙古、傣、彝、朝鲜、维吾尔文等)的超大型中文编码字符集强制性标准,其中收入汉字70000余个。中文的Windows操作系统默认使用GBK/GB2312编码。
Unicode:
很多传统的编码方式都有一个共同的问题,即容许电脑处理双语环境(通常使用拉丁字母以及其本地语言),但却无法同时支持多语言环境(指可同时处理多种语言混合的情况)。Unicode 是为了解决传统的字符编码方案的局限而产生的,例如ISO 8859所定义的字符虽然在不同的国家中广泛地使用,可是在不同国家间却经常出现不兼容的情况。Unicode的出现,能够使计算机实现跨语言、跨平台的文本转换及处理。
UTF-8:
因为Unicode编码使用2个字节存储一个字符。事实证明,对可以用ASCII表示的字符使用Unicode并不高效,因为Unicode比ASCII占用大一倍的空间,而对ASCII来说高字节的0对他毫无用处。为了解决这个问题,就出现了一些中间格式的字符集,他们被称为通用转换格式,即UTF(Unicode Transformation Format)。
UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码。由Ken Thompson于1992年创建。现在已经标准化为RFC 3629。UTF-8用1到4个字节编码UNICODE字符。用在网页上可以同一页面显示中文简体繁体及其它语言(如英文,日文,韩文)。
UTF-16:
UTF-16是Unicode字符编码五层次模型的第三层:字符编码表(Character Encoding Form,也称为 "storage format")的一种实现方式。即把Unicode字符集的抽象码位映射为16位长的整数(即码元)的序列,用于数据存储或传递。Unicode字符的码位,需要1个或者2个16位长的码元来表示,因此这是一个定长表示。Java语言默认使用UTF-16作为内存的字符存储格式。
二、各种乱码的处理
乱码的处理问题因为产生原因不同,需要使用不同的方式进行处理,现就不同的问题分情况讨论如下:
1.响应中的乱码处理
A.使用字节输出流输出响应:
Stringdata="传智播客";
response.getOutputStream().write(data.getBytes());
经实测不会发生乱码问题,原因是String的getBytes()方法默认使用本地平台默认编码将字符串转换为字节数组,而我们中文的windows操作系统默认使用GBK编码。而在用户端,浏览器默认也使用操作系统默认编码解析网页,在windows系统下默认也是GBK。发送端及接收端编码一致,所以不会产生乱码问题。
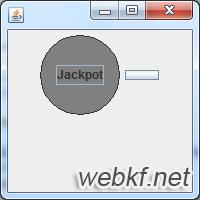
由于UTF-8编码是国际上通用的编码,所以我们在做Web开发时,通常使用UTF-8编码。但是如果使用getBytes("UTF-8")得到字节数组,并发送给客户端,此时会产生乱码问题。原因是因为getBytes("UTF-8")实际是指定按照UTF-8编码将字符串转换成字节数组。而浏览器此时默认仍然使用本地平台默认编码进行解码就会发生乱码问题。
此时的显示效果如下:
此时可以使用以下方式解决乱码问题:
方法一:手工调整浏览器的编码
点击鼠标右键,在弹出菜单中选择编码,之后选择UTF-8编码。
方法二:使用html规范中的meta标签设置
添加上述代码后,文字显示正常。
方法三:使用Response对象的setHeader()方法设置Content-Type头
另外,按照HTTP协议的规定,如果指定了消息正文的MIME类型后,浏览器就必须按照MIME类型解析,所以可以通过设置响应消息头Content-Type的值为text/html,并指定参数charset=UTF-8来使浏览器使用UTF-8解析页面。
方法四:使用Response对象的setContentType()方法设置MIME类型及编码
由于方法三的使用频率比较高,所以在制定Servlet规范时,JCP组织抽取了一个比较简单的方法,此方法与方法三的原理相同,只是更简单,在实际工作中,我们通常使用此方法指定MIME类型。
B.使用字符输出流输出响应:
Response对象的getWriter()方法可以返回一个PrintWriter对象,输出的内容会暂存在缓冲区中。当响应结束时,Tomcat使用默认编码ISO-8859-1将Response对象的响应消息正文转换为二进制数据输出给客户端,而浏览器使用本地平台默认编码进行解码,从而导致乱码。
处理方式:使用response.setCharacterEncoding("UTF-8")方法告知Tomcat使用UTF-8而不是ISO-8859-1对响应消息正文进行编码。另外,还需要使用response.setContentType("text/html;charset=UTF-8")告知浏览器使用UTF-8编码解码传递过来的数据。
修改后的显示效果如下:
2.请求中的乱码处理
在用户提交表单时,浏览器会按照当前页面的编码设置对中文字符进行编码,并将内容生成请求消息发送给服务器进行解析。Tomcat服务器得到请求消息后,会依据表单数据的位置不同,做不同的处理。
当提交方法(method)是POST时,表单数据会置于请求消息正文中,Tomcat默认使用ISO-8859-1对此部分内容进行解码,此时需要使用Request.setCharacterEncoding("UTF-8")告知服务器使用UTF-8编码对请求消息正文进行解码。
当提交方法(method)是GET时,表单数据会置于请求消息行中,并使用URL标准编码方式进行二次编码。而Tomcat得到此部分数据后,会先使用URL标准规范进行解码,然后默认使用ISO-8859-1再进行二次解码。此时如果使用Request.getParamater()方法得到String字符串得到的是经过ISO-8859-1解码的字符串,故会发生乱码问题。对于此种情况,需要将得到的字符串重新按照ISO-8859-1打回字节数组,再重新解码方可。
3.cookie中的乱码处理;
因为cookie是分别使用Set-Cookie和Cookie消息头在响应和请求消息头中进行传输的,而HTTP协议中,响应消息和请求消息中只能使用英文字符,中文字符是不安全字符无法直接使用。故在将中文存入Cookie中时,需要进行编码操作。我们可以使用URLEncoder工具类的encode()方法对中文进行编码,在读取时使用URLDecoder工具类的decode()方法进行解码。
使用URLEncoder.encode()方法对username字符串进行编码后再创建Cookie对象如下图:
使用URLDecoder.decode()方法对username字符串进行解码如下图:
三、 总结
以上的例子只是抛砖引玉,只要我们能抓住问题的关键,了解乱码的本质,那么乱码什么的都是浮云。
以上是 JavaWeb中文编码问题实例讲解 的全部内容, 来源链接: utcz.com/z/323605.html