Sql Server里删除数据表中重复记录的例子
[项目]
数据库中users表,包含u_name,u_pwd两个字段,其中u_name存在重复项,现在要实现把重复的项删除!
[分析]
1、生成一张临时表new_users,表结构与users表一样;
2、对users表按id做一个循环,每从users表中读出一个条记录,判断new_users中是否存在有相同的u_name,如果没有,则把它插入新表;如果已经有了相同的项,则忽略此条记录;
3、把users表改为其它的名称,把new_users表改名为users,实现我们的需要。
[程序]
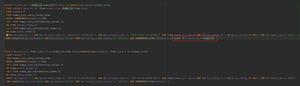
declare @id int,@u_name varchar(50),@u_pwd varchar(50)
set @id=1
while @id<1000
begin
if exists (select u_name from users where u_id=@id)
begin
select @u_name=u_name,@u_pwd=u_pwd from users where u_id=@id --获取源数据
if not exists (select u_name from new_users where u_name=@u_name) -- 判断是否有重复的U-name项
begin
insert into new_users(u_name,u_pwd) values(@u_name,@u_pwd)
end
end
set @id=@id+1
end
select * from new_users
以上是 Sql Server里删除数据表中重复记录的例子 的全部内容, 来源链接: utcz.com/z/315616.html