Java代码实现随机生成汉字的方法
一、背景知识
GB 2312-80 是中国国家标准简体中文字符集,全称《信息交换用汉字编码字符集·基本集》,由中国国家标准总局发布,1981年5月1日实施。GB2312 编码通行于中国大陆;新加坡等地也采用此编码。中国大陆几乎所有的中文系统和国际化的软件都支持 GB 2312。
GB2312 标准共收录 6763 个汉字,其中一级汉字 3755 个,二级汉字 3008 个;同时收录了包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母在内的 682 个字符。GB2312 的出现,基本满足了汉字的计算机处理需要,它所收录的汉字已经覆盖中国大陆 99.75% 的使用频率。对于人名、古汉语等方面出现的罕用字,GB2312 不能处理,这导致了后来 GBK 及 GB18030 汉字字符集的出现。
GB2312 中对所收汉字进行了“分区”处理,每区含有 94 个汉字/符号。这种表示方式也称为区位码。
- 01 - 09 区为特殊符号。
- 16 - 55 区为一级汉字,按拼音排序。
- 56 - 87 区为二级汉字,按部首/笔画排序。
- 10 - 15 区及 88 - 94 区则未有编码。举例来说,“啊”字是 GB2312 之中的第一个汉字,它的区位码就是 1601。
每个汉字及符号以两个字节来表示。第一个字节称为“高位字节”,第二个字节称为“低位字节”。“高位字节”使用了 0xA1 - 0xF7(把 01 - 87 区的区号加上 0xA0),“低位字节”使用了 0xA1 - 0xFE(把 01 - 94 位的位号加上 0xA0)。 由于一级汉字从 16 区起始,汉字区的“高位字节”的范围是 0xB0 - 0xF7,“低位字节”的范围是 0xA1 - 0xFE,占用的码位是 72 * 94 = 6768。其中有 5 个空位是 D7FA - D7FE。例如“啊”字在大多数程序中,会以两个字节,0xB0(第一个字节)0xA1(第二个字节)储存。(与区位码对比:0xB0 = 0xA0 + 16, 0xA1 = 0xA0 + 1)。
国家标准 GB 18030-2005《信息技术 中文编码字符集》,是中华人民共和国现时最新的内码字集,与 GB 2312-1980 完全兼容,与 GBK 基本兼容,支持 GB 13000 及 Unicode 的全部统一汉字,共收录汉字 70244 个。现行版本为国家质量监督检验总局和中国国家标准化管理委员会于2005年11月8日发布,2006年5月1日实施,为在中国境内所有软件产品支持的强制标准。
二、随机生成常用汉字的 C# 程序
新建Java项目,创建代码片段:
import java.io.UnsupportedEncodingException;
import java.util.Random;
/**
* 随机生成常见的汉字
*
* @author xuliugen
*
*/
public class GeneCharTest {
public static void main(String[] args) {
for (int i = 1; i < 24; i++) {
System.out.print(getRandomChar() + " ");
}
}
private static char getRandomChar() {
String str = "";
int hightPos; //
int lowPos;
Random random = new Random();
hightPos = (176 + Math.abs(random.nextInt(39)));
lowPos = (161 + Math.abs(random.nextInt(93)));
byte[] b = new byte[2];
b[0] = (Integer.valueOf(hightPos)).byteValue();
b[1] = (Integer.valueOf(lowPos)).byteValue();
try {
str = new String(b, "GBK");
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
System.out.println("错误");
}
return str.charAt(0);
}
}
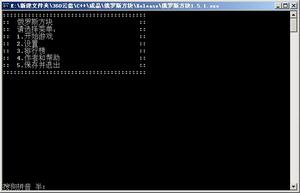
运行结果:
总结
以上是 Java代码实现随机生成汉字的方法 的全部内容, 来源链接: utcz.com/z/312727.html