解决使用openpyxl时遇到的坑
最近在用python处理Excel表格是遇到了一些问题
1, xlwt最多只能写入65536行数据, 所以在处理大批量数据的时候没法使用
2, openpyxl 这个库, 在使用的时候一直报错, 看下面代码
from openpyxl import Workbook
import datetime
wb = Workbook()
ws = wb.active
ws['A1'] = 42
ws.append([1,2,3])
ws['A2'] = datetime.datetime.now()
wb.save('test.xlsx')
报错信息如下
File "src\lxml\serializer.pxi", line 1652, in lxml.etree._IncrementalFileWriter.write TypeError: got invalid input value of type <class 'xml.etree.ElementTree.Element'>, expected string or Element
有没有人知道是什么原因呀? 惆怅!!!
got invalid input value of type <class ‘xml.etree.ElementTree.Element'>, expected string or Element
填坑:
出现这个问题好久了, 不知道怎么解决, 也去google 和baidu搜索, 一篇文章提到了可能是包冲突的问题, 抱着试一试的心态, 没想到解决了
lxml 这个包和openpyxl 起冲突, 解决办法, 先卸掉lxml
pip uninstall lxml
最后运行上面处理excel的代码, 运行成功, 无错误!!! 困扰了我很长时间的问题得以解决!!!
还有另一种方法:
由于lxml 包经常要用到, 所以每次卸载掉再安装实在是麻烦, 所以我有下面的想法
例如下面的代码, 从数据库中取数据存入表格
import pymysql
import pandas as pd
from sqlalchemy import create_engine
engine = create_engine("mysql+pymysql://user:password@ip:port/database",encoding='utf-8')
sql = """SELECT catalog_1 as '目录一',catalog_2 as '目录二',catagory as '目录三',
region as '区域',year as '年份',data as '数据',unit as '单位' from table
where catalog_1 = "农业" limit 100
"""
df = pd.read_sql_query(sql, con=engine)
# writer = pd.ExcelWriter(r'C:\Users\Administrator\Desktop\test.xlsx')
# df.to_excel(writer)
# writer.save()
这时候, 我们不选择to_excel() 这个函数, 而是选择使用to_csv() ; 即可避免openpyxl 和lxml 的冲突
df.to_csv(r'C:\Users\Administrator\Desktop\test.csv',index=False)
# 经过验证, 此种方法是行得通的
最后得到的csv 文件用Excel 可以直接打开, 也可以另存为*.xlsx文件
最终解决办法
今天发现我使用的openpyxl版本是3.0.2, 卸载此版本, 安装3.0.0版本
最新更新于2020-3-16, 经过测试, 此报错解除!
补充:Python—使用Openpyxl的dataframe_to_rows的一个小坑
这个坑说大不大,说小遇到了也头疼。
一般我们把dataframe直接写到Excel文件,直接 df.to_excel即可。不过如果想把多个表格写入同一个工作表呢,那就需要用openpyxl的dataframe_to_rows功能。
看下面一段代码。
import pandas as pd
from openpyxl import Workbook
from openpyxl.utils.dataframe import dataframe_to_rows
df1=pd.DataFrame([[1,4],[2,5],[3,6]] ,index=['a','b','c'],columns=['a','b'])
df2=pd.DataFrame([[1,4],[2,5],[3,6],[7,8]] ,index=['d','e','f','g'],columns=['a','b'])
wb=Workbook()
ws=wb.active #打开工作表
#把df1写入工作表
for row in dataframe_to_rows(df1):
ws.append(row)
#换行
ws.append([])
#把df2写入工作表
for row in dataframe_to_rows(df2):
ws.append(row)
wb.save('text.xlsx')
这段代码就是把df1,df2都写入到一个工作表,但一看结果,傻了,怎么标题行和内容之间多了空行啊
看看空行是如何产生的呢
原来多了一个None啊,难怪是空行,目测None是index带来的,那就把index去掉呗
这回None是没有了,但是index的内容也想要显示,怎么办呢,这么办:
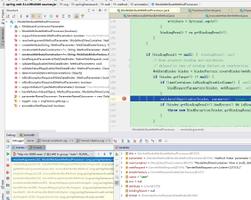
哈哈,这样就完美了。这里reset_index的意思就是把index列,变成普通列,比如:
如上图,如果直接reset_index,index列变成普通列,但是列头自动变成了index,这可不好,所以先给index列赋值,也就是df1.index.name=‘code'
最后代码如下
import pandas as pd
from openpyxl import Workbook
from openpyxl.utils.dataframe import dataframe_to_rows
df1=pd.DataFrame([[1,4],[2,5],[3,6]] ,index=['a','b','c'],columns=['a','b'])
df2=pd.DataFrame([[1,4],[2,5],[3,6],[7,8]] ,index=['d','e','f','g'],columns=['a','b'])
wb=Workbook()
ws=wb.active #打开工作表
df1.index.name='code1'
df2.index.name='code2'
#把df1写入工作表
for row in dataframe_to_rows(df1.reset_index(),index=False):
ws.append(row)
#换行
ws.append([])
#把df2写入工作表
for row in dataframe_to_rows(df2.reset_index(),index=False):
ws.append(row)
wb.save('text.xlsx')
结果,哈哈,完美
以上为个人经验,希望能给大家一个参考,也希望大家多多支持。如有错误或未考虑完全的地方,望不吝赐教。
以上是 解决使用openpyxl时遇到的坑 的全部内容, 来源链接: utcz.com/z/311522.html