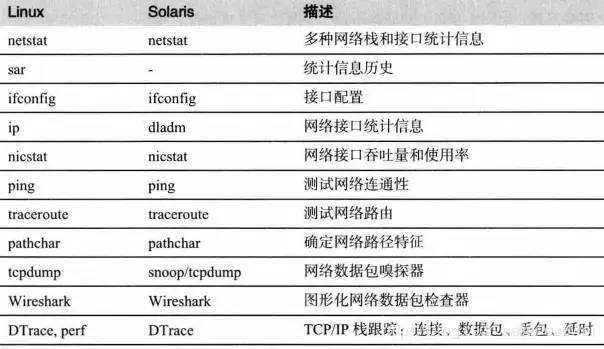
etcd 性能测试与调优
本文内容纲要:
- 理解 etcd 的性能- 时间参数
- 快照
- 磁盘
- 网络
- 数据规模
etcd 是一个分布式一致性键值存储。其主要功能有服务注册与发现、消息发布与订阅、负载均衡、分布式通知与协调、分布式锁、分布式队列、集群监控与 leader 选举等。
**1.**etcd 性能优化
官方文档原文:https://github.com/etcd-io/etcd/blob/master/Documentation/tuning.md 译文参考:https://skyao.gitbooks.io/learning-etcd3/content/documentation/op-guide/performance.html
理解 etcd 的性能
决定 etcd 性能的关键因素,包括:
- 延迟 (latency):延迟是完成操作的时间。
- 吞吐量 (throughput):吞吐量是在某个时间期间之内完成操作的总数量。当 etcd 接收并发客户端请求时,通常平均延迟随着总体吞吐量增加而增加。
在通常的云环境,比如 Google Compute Engine (GCE) 标准的 n-4 或者 AWS 上相当的机器类型,一个三成员 etcd 集群在轻负载下可以在低于 1 毫秒内完成一个请求,并在重负载下可以每秒完成超过 30000 个请求。
etcd 使用 Raft 一致性算法来在成员之间复制请求并达成一致。一致性性能,特别是提交延迟,受限于两个物理约束:网络 IO 延迟和磁盘 IO 延迟。完成一个 etcd 请求的最小时间是成员之间的网络往返时延 (Round Trip Time / RTT),加需要提交数据到持久化存储的 fdatasync 时间。在一个数据中心内的 RTT 可能有数百毫秒。在美国典型的 RTT 是大概 50ms, 而在大陆之间可以慢到 400ms。旋转硬盘(注:指传统机械硬盘) 的典型 fdatasync 延迟是大概 10ms。对于 SSD 硬盘, 延迟通常低于 1ms。为了提高吞吐量, etcd 将多个请求打包在一起并提交给 Raft。这个批量策略让 etcd 在重负载试获得高吞吐量。也有其他子系统影响到 etcd 的整体性能。每个序列化的 etcd 请求必须通过 etcd 的 boltdb 支持的(boltdb-backed) MVCC 存储引擎, 它通常需要 10 微秒来完成。etcd 定期递增快照它最近实施的请求,将他们和之前在磁盘上的快照合并。这个过程可能导致延迟尖峰(latency spike)。虽然在 SSD 上这通常不是问题,在 HDD 上它可能加倍可观察到的延迟。而且,进行中的压缩可以影响 etcd 的性能。幸运的是,压缩通常无足轻重,因为压缩是错开的,因此它不和常规请求竞争资源。RPC 系统,gRPC,为 etcd 提供定义良好,可扩展的 API,但是它也引入了额外的延迟,尤其是本地读取。
Etcd 的默认配置在本地网络环境(localhost)下通常能够运行的很好,因为延迟很低。然而,当跨数据中心部署 Etcd 或网络延时很高时,etcd 的心跳间隔或选举超时时间等参数需要根据实际情况进行调整。
网络并不是导致延时的唯一来源。不论是 Follower 还是 Leader,其请求和响应都受磁盘 I/O 延时的影响。每个 timeout 都代表从请求发起到成功返回响应的总时间。
时间参数
Etcd 底层的分布式一致性协议依赖两个时间参数来保证节点之间能够在部分节点掉钱的情况下依然能够正确处理主节点的选举。第一个参数就是所谓的心跳间隔,即主节点通知从节点它还是领导者的频率。实践数据表明,该参数应该设置成节点之间 RTT 的时间。Etcd 的心跳间隔默认是 100 毫秒。第二个参数是选举超时时间,即从节点等待多久没收到主节点的心跳就尝试去竞选领导者。Etcd 的选举超时时间默认是 1000 毫秒。
调整这些参数值是有条件的,此消波长。心跳间隔值推荐设置为临近节点间 RTT 的最大值,通常是 0.5~1.5 倍 RTT 值。如果心跳间隔设得太短,那么 Etcd 就会发送没必要的心跳信息,从而增加 CPU 和网络资源的消耗;如果设得太长,就会导致选举等待时间的超时。如果选举等待时间设置的过长,就会导致节点异常检测时间过长。评估 RTT 值的最简单的方法是使用 ping 的操作。
选举超时时间应该基于心跳间隔和节点之间的平均 RTT 值。选举超时必须至少是 RTT 10 倍的时间以便对网络波动。例如,如果 RTT 的值是 10 毫秒,那么选举超时时间必须至少是 100 毫秒。选举超时时间的上线是 50000 毫秒(50 秒),这个时间只能只用于全球范围内分布式部署的 Etcd 集群。美国大陆的一个 RTT 的合理时间大约是 130 毫秒,美国和日本的 RTT 大约是 350~400 毫秒。如果算上网络波动和重试的时间,那么 5 秒是一次全球 RTT 的安全上线。因为选举超时时间应该是心跳包广播时间的 10 倍,所以 50 秒的选举超时时间是全局分布式部署 Etcd 的合理上线值。
心跳间隔和选举超时时间的值对同一个 Etcd 集群的所有节点都生效,如果各个节点都不同的话,就会导致集群发生不可预知的不稳定性。Etcd 启动时通过传入启动参数或环境变量覆盖默认值,单位是毫秒。示例代码具体如下:
$ etcd --heartbeat-interval=100 --election-timeout=500# 环境变量值
$ ETCD_HEARTBEAT_INTERVAL=100 ETCD_ELECTION_TIMEOUT=500 etcd
快照
Etcd 总是向日志文件中追加 key,这样一来,日志文件会随着 key 的改动而线性增长。当 Etcd 集群使用较少时,保存完整的日志历史记录是没问题的,但如果 Etcd 集群规模比较大时,那么集群就会携带很大的日志文件。为了避免携带庞大的日志文件,Etcd 需要做周期性的快照。快照提供了一种通过保存系统的当前状态并移除旧日志文件的方式来压缩日志文件。
快照调优
为 v2 后端存储创建快照的代价是很高的,所以只用当参数累积到一定的数量时,Etcd 才会创建快照文件。默认情况下,修改数量达到 10000 时才会建立快照。如果 Etcd 的内存使用和磁盘使用过高,那么应该尝试调低快照触发的阈值,具体请参考如下命令。
启动参数:
$ etcd --snapshot-count=5000环境变量:
$ ETCD_SNAPSHOT_COUNT=5000 etcd磁盘
etcd 的存储目录分为 snapshot 和 wal,他们写入的方式是不同的,snapshot 是内存直接 dump file。而 wal 是顺序追加写,对于这两种方式系统调优的方式是不同的,snapshot 可以通过增加 io 平滑写来提高磁盘 io 能力,而 wal 可以通过降低 pagecache 的方式提前写入时序。因此对于不同的场景,可以考虑将 snap 与 wal 进行分盘,放在两块 SSD 盘上,提高整体的 IO 效率,这种方式可以提升 etcd 20% 左右的性能。
etcd 集群对磁盘 I/O 的延时非常敏感,因为 Etcd 必须持久化它的日志,当其他 I/O 密集型的进程也在占用磁盘 I/O 的带宽时,就会导致 fsync 时延非常高。这将导致 Etcd 丢失心跳包、请求超时或暂时性的 Leader 丢失。这时可以适当为 Etcd 服务赋予更高的磁盘 I/O 权限,让 Etcd 更稳定的运行。在 Linux 系统中,磁盘 I/O 权限可以通过 ionice 命令进行调整。
nux 默认 IO 调度器使用 CFQ 调度算法,支持用 ionice 命令为程序指定 IO 调度策略和优先级,IO 调度策略分为三种:
- Idle :其他进程没有磁盘 IO 时,才进行磁盘 IO
- Best Effort:缺省调度策略,可以设置 0-7 的优先级,数值越小优先级越高,同优先级的进程采用 round-robin 算法调度;
- Real Time :立即访问磁盘,无视其它进程 IO
- None 即 Best Effort,进程未指定策略和优先级时显示为 none,会使用依据 cpu nice 设置计算出优先级
Linux 中 etcd 的磁盘优先级可以使用 ionice 配置:
$ ionice -c2 -n0 -p `pgrep etcd`网络
etcd 中比较复杂的是网络的调优,因此大量的网络请求会在 peer 节点之间转发,而且整体网络吞吐也很大,但是还是再次强调不建议大家调整系统参数,大家可以通过修改 etcd 的 --heartbeat-interval 与 --election-timeout 启动参数来适当提高高吞吐网络下 etcd 的集群鲁棒性,通常同步吞吐在 100MB 左右的集群可以考虑将 --heartbeat-interval 设置为 300ms-500ms,--election-timeout 可以设置在 5000ms 左右。此外官方还有基于 TC 的网络优先传输方案,也是一个比较适用的调优手段。
如果 etcd 的 Leader 服务大量并发客户端,这就会导致 follower 的请求的处理被延迟因为网络延迟。follower 的 send buffer 中能看到错误的列表,如下所示:
dropped MsgProp to 247ae21ff9436b2d since streamMsg's sending buffer is fulldropped MsgAppResp to 247ae21ff9436b2d since streamMsg's sending buffer is full
这些错误可以通过提高 Leader 的网络优先级来提高 follower 的请求的响应。可以通过流量控制机制来提高:
// 针对 2379、2380 端口放行$ tc qdisc add dev eth0 root handle 1: prio bands 3
$ tc filter add dev eth0 parent 1: protocol ip prio 1 u32 match ip sport 2380 0xffff flowid 1:1
$ tc filter add dev eth0 parent 1: protocol ip prio 1 u32 match ip dport 2380 0xffff flowid 1:1
$ tc filter add dev eth0 parent 1: protocol ip prio 2 u32 match ip sport 2379 0xffff flowid 1:1
$ tc filter add dev eth0 parent 1: protocol ip prio 2 u32 match ip dport 2379 0xffff flowid 1:1
// 查看现有的队列
$ tc -s qdisc ls dev enp0s8
qdisc prio 1: root refcnt 2 bands 3 priomap 1 2 2 2 1 2 0 0 1 1 1 1 1 1 1 1
Sent 258578 bytes 923 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
// 删除队列
$ tc qdisc del dev enp0s8 root
数据规模
etcd 的硬盘存储上限(默认是 2GB), 当 etcd 数据量超过默认 quota 值后便不再接受写请求,可以通过设置 --quota-backend-bytes 参数来增加存储大小,quota-backend-bytes 默认值为 0,即使用默认 quota 为 2GB,上限值为 8 GB,具体说明可参考官方文档:https://github.com/etcd-io/etcd/blob/master/Documentation/dev-guide/limit.md 。
The default storage size limit is 2GB, configurable with `--quota-backend-bytes` flag. 8GB is a suggested maximum size for normal environments and etcd warns at startup if the configured value exceeds it.以下摘自 当 K8s 集群达到万级规模,阿里巴巴如何解决系统各组件性能问题?
阿里进行了深入研究了 etcd 内部的实现原理,并发现了影响 etcd 扩展性的一个关键问题在底层 bbolt db 的 page 页面分配算法上:随着 etcd 中存储的数据量的增长,bbolt db 中线性查找 “连续长度为 n 的 page 存储页面” 的性能显著下降。 为了解决该问题,我们设计了基于 segregrated hashmap 的空闲页面管理算法,hashmap 以连续 page 大小为 key, 连续页面起始 page id 为 value。通过查这个 segregrated hashmap 实现 O(1) 的空闲 page 查找,极大地提高了性能。在释放块时,新算法尝试和地址相邻的 page 合并,并更新 segregrated hashmap。更详细的算法分析可以见已发表在 CNCF 博客的博文。 通过这个算法改进,我们可以将 etcd 的存储空间从推荐的 2GB 扩展到 100GB,极大地提高了 etcd 存储数据的规模,并且读写无显著延迟增长。 pull request :https://github.com/etcd-io/bbolt/pull/141
目前社区已发布的 v3.4 系列版本并没有说明支持数据规模可达 100 G。
2.
etcd 性能测试
测试环境:本机 mac 使用 virtualbox 安装 vm,所有 etcd 实例都是运行在在 vm 中的 docker 上
参考官方文档:https://github.com/etcd-io/etcd/blob/master/Documentation/op-guide/performance.md
安装 etcd 压测工具 benchmark:
1. // 下载benchmarck包$ go get go.etcd.io/etcd/tools/benchmark
2. // 将benchmarck二进制文件放在gopath目录下
3. // 验证是否安装成功
$ benchmark // 会显示help信息
本文仅对 etcd v3.3.10 以及 v3.4.1 进行压测。
写入测试
# write to leaderbenchmark --endpoints=${HOST_1} --target-leader --conns=1 --clients=1 \
put --key-size=8 --sequential-keys --total=10000 --val-size=256
benchmark --endpoints=${HOST_1} --target-leader --conns=100 --clients=1000 \
put --key-size=8 --sequential-keys --total=100000 --val-size=256
# write to all members
benchmark --endpoints=${HOST_1},${HOST_2},${HOST_3} --conns=100 --clients=1000 \
put --key-size=8 --sequential-keys --total=100000 --val-size=256
本文内容总结:理解 etcd 的性能,时间参数,快照,磁盘,网络,数据规模,
原文链接:https://www.cnblogs.com/lizhewei/p/13036463.html
以上是 etcd 性能测试与调优 的全部内容, 来源链接: utcz.com/z/297001.html