
【正则表达式教程】深入理解正则引擎内核
正则引擎
正则表达式描述了一种搜索模式,可以将其应用于文本数据来查找匹配项。正则表达式通常被编译为可以在计算机上有效执行的形式。实际的搜索操作由正则表达式引擎执行,该引擎利用编译后的正则表达式。
对于程序员来说,要编写良好的正则表达式,了解这些引擎的工作方式是很有帮助的。 有几种类型的引擎,通常实现方式为有限自动机。实际上,正则表达式与自动机理论和常规语言有关。正则表达式的语法和语义已由IEEE标准化为POSIX BRE和ERE。但是,有许多非标准的方式。通常,差异是细微的。设计正则表达式的程序员必须知道要使用的正则引擎所遵循的方式。
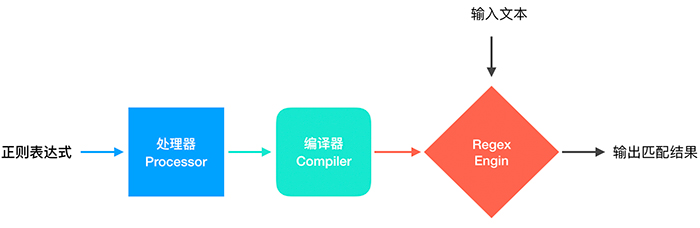
正则表达式引擎接收两个输入:正则表达式模式和要检索的目标字符串。程序员将正则表达式指定为字符串。虽然可以将引擎设计为直接使用字符串,但是有一种更好,更有效的方法。已经证明,对于每个正则表达式都有一个等效的有限状态机(FSM)或有限自动机(FA)。换句话说,可以将正则表达式建模为状态的有限集合,并基于在一个状态下接收到的输入来在这些状态之间进行转换。因此,编译器的工作是将原始的regex字符串转换为有限的自动机,该自动机可以由引擎更轻松地执行。
在一些实现方式中,可以在编译器之前调用预处理器。替换宏或字符类,例如将\ p {Alpha}替换为[a-zA-Z] 。预处理器还执行特定于语言环境的替换。
让我们注意,对于正则表达式引擎的执行过程并没有标准定义。有些人可能考虑将解析,编译和执行作为引擎的一部分。
下面看一下自动机时如何应用于正则表达式的
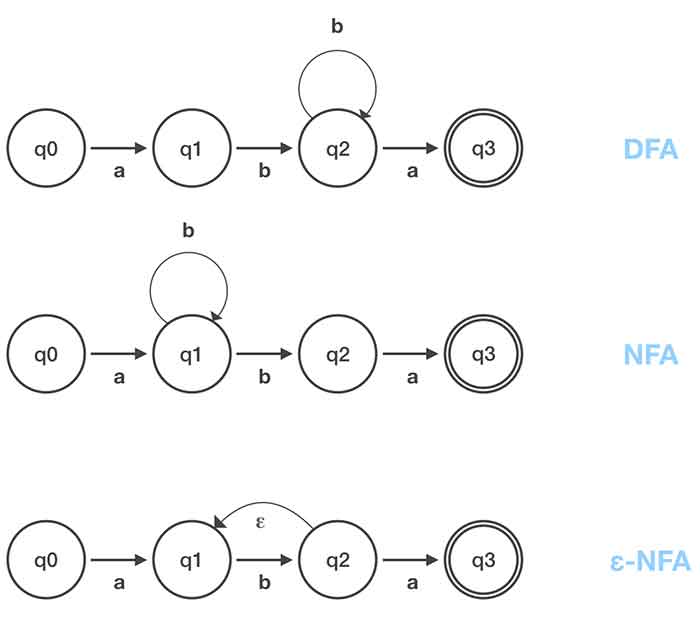
有两种自动机:
- 确定性有限自动机(DFA):给定一个状态和一个输入,就有一个定义明确的输出状态。
- 非确定性有限自动机(NFA):给定一个状态和一个输入,可能会有多个可能的输出状态。NFA的一种变体是ε-NFA ,即使没有输入也可能发生状态转换。
已经证明,每个DFA都可以转换为NFA,反之亦然。在附图中,所有三个自动机都是等效的,代表正则表达式abb*a (或ab+a )。对于NFA,当在状态q1中接收到“b”时,自动机可以保留在q1中或移至q2。因此,这是不确定的。对于ε-NFA,即使没有输入,自动机也可以从q2移至q1。有人说
正则表达式可以被认为是用于描述文本模式的有限自动机的一种用户友好替代方法。
有哪些不同类型的正则表达式引擎?
正则表达式引擎可以实现为DFA或NFA。但是,简单来说,可以将正则表达式引擎分类如下:
- Text-Directed(文本导向):引擎在移至输入的下一个字符之前会尝试正则表达式的所有路径。因此,该引擎不会后退。由于所有路径都是一次尝试的,因此它将返回最长的匹配项。例如,输入“ SetValue”上的(Set | SetValue)将匹配“ SetValue”。
- Regex-Directed(正则表达式定向):如果引擎在某个位置发生故障,它将回溯以尝试替代路径。尝试按从左到右的顺序进行路径。因此,即使稍后在另一条路径中有更长的匹配项,它也会返回最左边的匹配项。例如,输入“ SetValue”上的(Set | SetValue)将匹配“ Set”。
大多数现代引擎都是用正则表达式导向的,因为这是实现某些特定功能(如懒惰量词和反向引用)的唯一方法。原子分组和所有格修饰符可以进一步控制回溯。
当今的正则表达式功能丰富,不能总是作为自动机有效地实现。环视断言和后向引用很难实现为NFA。大多数正则表达式引擎使用递归回溯。
如果使用递归回溯,性能差的正则表达式会导致大量回溯和通过替代路径进行搜索。时间复杂度呈指数增长。汤普森的NFA (或等效的DFA)效率更高,并保持线性时间复杂度。一种折衷方案是仅在需要反向引用时才使用Thompson算法并回溯。 GNU的awk和grep工具通常使用DFA,并在使用反向引用时切换到NFA 。
Ruby使用非递归回溯,但是对于性能差的正则表达式,它也呈指数增长。Ruby的引擎称为Oniguruma 。
由于自动机在任何给定时间仅处于一种状态,因此DFA比NFA效率更高。传统的NFA在失败之前会尝试所有路径。POSIX NFA会尝试每条路径以找到最长的匹配项。文本控制的DFA花费更多的时间和内存来分析和编译正则表达式,但是可以对其进行优化从而使其可以进行实时编译。
就代码大小而言,ed (1979)中的NFA regex是大约350行C代码。亨利·斯宾塞(Henry Spencer)在1986年实现为1900行,而他在1992年实现的POSIX DFA则为4500行。
正则表达式引擎遵循哪些基本规则?
正则表达式引擎以从左到右的顺序一次执行一个正则表达式字符。输入的字符串本身按从左到右的顺序一次解析一个字符。匹配一个字符后,该字符就从输入中消耗掉,引擎移至下一个输入字符。
默认情况下,引擎是贪婪的。当使用量词(例如* +?{m,n} )时,它将尝试匹配输入字符串中尽可能多的字符。引擎也很热心,它会及时的报告发现的第一个匹配项。
如果正则表达式与输入中的字符不匹配,则它会做两件事。它将回溯到较早的贪婪操作,并查看较小的贪婪匹配是否会导致匹配。否则,引擎将移至下一个字符,并尝试再次在此位置匹配正则表达式。无论哪种方式,引擎始终知道其在正则表达式中的当前位置。如果正则表达式指定了替代项,则如果一个搜索路径失败,则引擎将回溯以匹配下一个替代项。因此,引擎还存储回溯位置。
通过示例解释“贪婪”和“渴望”的概念
使用正则表达式 a.*o 来匹配字符串 “cat dog mouse” 。即使“at do”是有效的匹配,但由于引擎的贪婪性,因此它给出的匹配是“ at dog mo”。为了避免这种贪婪的行为,我们可以使用惰性或非贪婪的匹配:a.*?o将匹配“at do”。除了在量词后面使用问号之外,在某些正则引擎中(例如 PCRE)还可以使用'U'修饰符来逆转正则表达式的贪婪性。
非贪婪的\w{2,3}?输入“abc”时将匹配“ab”而不是“abc”。假设正则表达式是\w{2,3}?$ ,则即使正则表达式是非贪婪的,匹配也是“ abc”而不是“ bc”。这是因为引擎渴望报告发现的第一个匹配项。因此,它首先匹配“ ab”,然后看到$不匹配“ c”。此时,引擎将不会向后退到位置“ b”。它将保留在“ a”处,并比较由于{2,3}而引起的第三个字符。因此,它找到“abc”作为匹配项。然后它就急切地报告匹配完成了。
另一个例子是使用正则表达式(self)?(selfish)? 匹配“selfish”。由于引擎的急切性,引擎将报告“self”为匹配项。但是,文本导向的引擎将报告“selfish”为匹配项。
通过示例解释“回溯”的概念
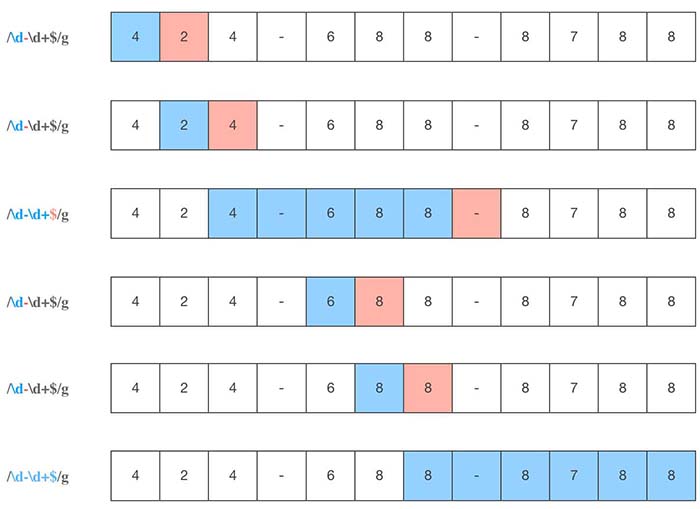
让我们使用正则表达式/-\d+$/g来匹配字符串“424-688-8799”。正则表达式引擎会将-\d+匹配为“-688”,但是当看到$时,则声明不匹配。此时,它将回溯到正则表达式的开始,并且目标字符串中的当前位置将从“-”前进到“6”。在此示例中,仅发生一次回溯。假设我们在相同的字符串上使用正则表达式/\d-\d+$/g来匹配 ,将会产生五个回溯,如图所示。
引擎也可以回溯部分路线。让我们将/A\d+\D?./g应用于“A1234”。正则A\d+\D?会匹配到“ A1234”,但当引擎到达时点.时,没有匹配。它将回溯到\d +并放弃一个字符,因此A\d+现在仅匹配“ A123”。随着引擎的继续,点.将与“4”匹配。
回溯的另一个示例是pic(ket|nic)。如果字符串是“Let's picnic。”,则引擎会将pic匹配为“pic”,但是下一个字符匹配(k vs. n)将失败。引擎知道还有其他选择。它将回溯到“pic”末尾并处理第二种选择。
本文转载自:迹忆客(https://www.jiyik.com)
以上是 【正则表达式教程】深入理解正则引擎内核 的全部内容, 来源链接: utcz.com/z/290331.html

![正则表达式中 [\s\S]* 什么意思 居然能匹配所有字符 [] 不是范围描述符吗?](/wp-content/uploads/thumbs/270159_thumbnail.jpg)


