Notes on Convolutional Neural Networks 中文翻译
这是 Jake Bouvrie 在 2006 年写的关于 CNN 的训练原理,虽然文献老了点,不过对理解经典CNN的训练过程还是很有帮助的。该作者是剑桥的研究认知科学的。
原文:https://www.wenjiangs.com/wp-content/uploads/2022/03/cnn_tutorial.pdf
1 引言
这个文档是为了讨论 CNN 的推导和执行步骤的,并加上一些简单的扩展。因为 CNN 包含着比权重还多的连接,所以结构本身就相当于实现了一种形式的正则化了。另外CNN本身因为结构的关系,也具有某种程度上的平移不变性。这种特别的NN可以被认为是以数据驱动的形式在输入中可以自动学习过滤器来自动的提取特征。我们这里提出的推导是具体指2D数据和卷积的,但是也可以无障碍扩展到任意维度上。
我们首先以在全连接网络上说明经典的 Bp 是如何工作的,然后介绍了在 2D CNN 中 BP 是如何在过滤器和子采样层上进行权值更新的。通过这些论述,我们强调了模型实际执行的高效的重要性,并给出一小段MATLAB代码来辅助说明这些式子。当然在CNN上也不能过度的夸大高效代码的重要性(毕竟结构放在那里了,就是很慢的)。接下来就是讨论关于如何将前层学到的特征图自动组合的主题,并具体的考虑学习特征图的稀疏组合问题。
免责声明:这个粗糙的笔记可能包含错误,各位看官且看且谨慎。(作者的免责声明)。
2 用 BP 训练全连接网络
在许多文献中,可以发现经典的CNN是由卷积和子采样操作互相交替组成的,然后在最后加上一个普通的多层网络的结构:最后几层(最靠经输出层的部分)是全连接1D层。当准备好将最后的2D特征图作为输入馈送到这个全连接1D网络的时候,也能很方便的将所有的输出图中表现的特征连接到一个长输入向量中,并往回使用BP进行训练。这个标准的BP算法将会在具体介绍CNN的情况之前介绍(【1】中有更详细的介绍)。
2.1 前向传播
在推导过程中,我们的损失函数采用的是误差平方和损失函数。对于一个有着 c 个类别和 N 个训练样本的多类问题,这个损失函数形式如下:
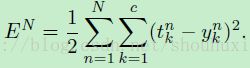 (公式1)
(公式1)
这里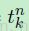 是第 n 个样本相对应的目标(标签)的第 k 维,
是第 n 个样本相对应的目标(标签)的第 k 维,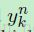 是由模型的第n 个样本预测得到的目标(标签)的第 k 维。对于多分类问题,这个目标通常是以“one-of-c”编码的形式存在的,当
是由模型的第n 个样本预测得到的目标(标签)的第 k 维。对于多分类问题,这个目标通常是以“one-of-c”编码的形式存在的,当 是属于第k 类的,那么
是属于第k 类的,那么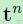 的第 k 个元素就是正的,其他的元素就是 0 或者是负的(这取决于激活函数的选择)。
的第 k 个元素就是正的,其他的元素就是 0 或者是负的(这取决于激活函数的选择)。
因为在整个训练集上的误差只是简单的将每个样本产生的误差进行相加得到的,所以这里先在单个样本(第 n 个)上用BP来做讲解:
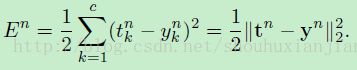 (公式2)
(公式2)
在普通的全连接网络上,我们能够用下面的BP规则的形式来对 E求关于权重的偏导。 这里 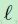 指示当前的第几层,输出层为第
指示当前的第几层,输出层为第
L 层,而输入层(原始数据层)为第1 层。这里第层(当前层)的输出是:
 (公式3)
(公式3)
这里输出的激活函数 f(·)通常是选择逻辑(sigmoid)函数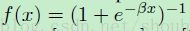 或者双曲线
或者双曲线
tangent 函数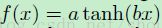 。
。
这个逻辑函数可以将【-∞,+∞】的数映射到【0,1】,而这个双曲线 tangent函数可以将【-∞,+∞】的数映射到【-a,+a】。因此双曲线tangent函数的输出通常是靠近 0 ,而sigmoid函数的输出通常是非 0 的。然而对训练数据进行归一化到 0 均值和单位方差(方差为1)可以在梯度下降上改善收敛。在基于一个归一化的数据集上,通常更喜欢选择双曲线 tangent函数。LeCun建议 a =
1.7159;b = 2 / 3。这样非线性最大化的点会出现在 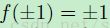 ,因此当期望的训练目标以值
,因此当期望的训练目标以值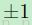 进行归一化的时候,就可以可以避免在训练的时候饱和的问题(估计就是防止训练目标分布的太集中在0周围了,这样可以使它们更加合理的分布)。
进行归一化的时候,就可以可以避免在训练的时候饱和的问题(估计就是防止训练目标分布的太集中在0周围了,这样可以使它们更加合理的分布)。
2.2 后向传播
网络中我们需要后向传播的“ 误差”可以被认为是关于有偏置项扰动的每个单元的 “敏感性”(这个解释来自于Sebastian Seung)。也就是说:
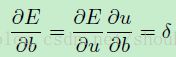 (公式4)
(公式4)
因为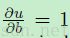 ,所以偏置的敏感性其实等于一个单元的所有输入产生的误差偏导。下面的就是从高层到低层的BP:
,所以偏置的敏感性其实等于一个单元的所有输入产生的误差偏导。下面的就是从高层到低层的BP:
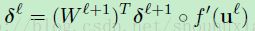 (公式5)
(公式5)
这里的“o” 表示是 逐原始相乘的。对于公式2中的误差函数,输出层神经元的敏感性如下:
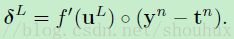 (公式6)
(公式6)
最后,关于某个给定的神经元的更新权重的delta-rule就是对那个神经元的输入部分进行复制,只是用神经元的delta进行缩放罢了(其实就是如下面公式7的两个相乘而已)。在向量的形式中,这相当于输入向量(前层的输出)和敏感性向量的外积:
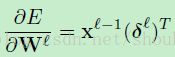 (公式7)
(公式7)
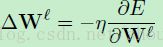 (公式8)
(公式8)
和公式4的偏置更新的表现形式相类似。在实际操作中这里的学习率一般是每个权重都有不同的学习率即: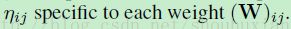
3 CNN
通常卷积层都是有子采样层的附加以此来减少计算时间并且逐步的建立更深远的空间和构型的不变性。在照顾特异性的同时也需要一个小的子采样因子,当然这个不是新方法,但是这个概念却简单而又有效。哺乳动物的视觉皮层和在【12 87】中的模型着重的介绍了这些方面,在过去的10年中听觉神经科学的发展让我们知道在不同动物的皮层上primary和belt听觉领域中有相同的设计模型【6 11 9】.层级分析和学习结构也许就是听觉领域获得成功的关键。
3.1 卷积层
这里接着谈论网络中关于卷积层的BP更新。在一个卷积层中,前层的特征映射图是先进行卷积核运算然后再放入一个激活函数来得到特征映射图作为输出。每个输出图也许是有许多个图的卷积组合而成的。通常如下面的公式:
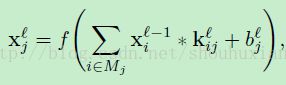 (公式9)
(公式9)
这里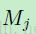 表示选的第几个输入图,在MATLAB中这里的卷积是“valid”边缘处理的。通常对输入图的选择包括all-pairs或者是all-triplets,但是下面会讨论如何学习组合的。每个输出图都有个额外的偏置 b,然而对于一个具体的输出图来说,输入图是有着不同的卷积核的。也就是说如果输出图 j 和 k 都是在输入图 i上相加得到的,应用在图 i 上的卷积和关于输出图 j 和 k 是不同的。
表示选的第几个输入图,在MATLAB中这里的卷积是“valid”边缘处理的。通常对输入图的选择包括all-pairs或者是all-triplets,但是下面会讨论如何学习组合的。每个输出图都有个额外的偏置 b,然而对于一个具体的输出图来说,输入图是有着不同的卷积核的。也就是说如果输出图 j 和 k 都是在输入图 i上相加得到的,应用在图 i 上的卷积和关于输出图 j 和 k 是不同的。
3.1.1 计算梯度
我们假设每个卷积层 后面都跟着一个下采样层 +1.在BP算法中,为了计算第 层中的单元的敏感性,需要先计算与当前层中这个单元相关联的下一层的敏感性的总和,并乘以下一层(第+1层)与这个单元之间的权重参数得到传递到这一层这个单元的敏感性。并用当前层的输入u 的激活函数的偏导乘以这个量(这里所要表达的就是BP的想法,如果熟悉BP那么这里比较绕口的意思就能很好的明白了)。
在一个卷积层并后面跟个下采样层的情况中,在下采样层中所关联的图 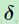 中的一个像素相当于卷积层输出图中的像素块(后来的池化的想法)。因此在第 层中的一个图上的每个单元只与第 +1层中相对应的图中的一个单元相连(多对一的关系)。为了高效的计算第层的敏感性,我们可以对下采样层中的敏感图进行上采样去保证与卷积层图具有相同的尺寸,随后只需要将第 +1层中的上采样敏感图与第层中的激活函数偏导图逐元素相乘即可。在下采样层图中定义的“权重”全等于
中的一个像素相当于卷积层输出图中的像素块(后来的池化的想法)。因此在第 层中的一个图上的每个单元只与第 +1层中相对应的图中的一个单元相连(多对一的关系)。为了高效的计算第层的敏感性,我们可以对下采样层中的敏感图进行上采样去保证与卷积层图具有相同的尺寸,随后只需要将第 +1层中的上采样敏感图与第层中的激活函数偏导图逐元素相乘即可。在下采样层图中定义的“权重”全等于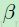 (一个常量,见部分3.2),所以只是将前面步骤的结果用
(一个常量,见部分3.2),所以只是将前面步骤的结果用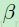 来进行缩放以达到计算
来进行缩放以达到计算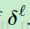 的结果。我们能在卷积层的每个图 j 中进行同样的计算,并用子采样层中相对应的图进行搭配:
的结果。我们能在卷积层的每个图 j 中进行同样的计算,并用子采样层中相对应的图进行搭配:
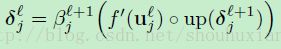 (公式10)
(公式10)
这里up(·)表示一个上采样操作,如果子采样层用因子 n 来子采样,那么就简单的将输入中的每个像素在输出中进行水平和竖直tiles操作 n次。正如下面说的,高效的执行这个函数的一个可能的方法是通过使用Kronecker积:
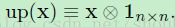 (公式11)
(公式11)
现在,我们有了给定图的敏感性,我们能够立刻通过将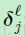 中所有的实体进行累加来简单的计算偏置的梯度:
中所有的实体进行累加来简单的计算偏置的梯度:
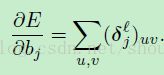 (公式11)
(公式11)
最后,除了许多链接中交叉共享相同权重的情况,核权重的梯度可以通过BP来进行计算。因此,我们将在所有连接中提到这个权重的权重梯度进行累加,就像对偏置项的操作一样:
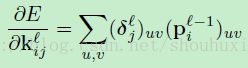 (公式12)
(公式12)
这里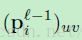 是
是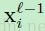 中的块,为了计算输出卷积图
中的块,为了计算输出卷积图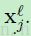 中位于(u,v)的元素而在卷积中用
中位于(u,v)的元素而在卷积中用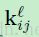 与其进行逐元素相乘。乍一看,我们可能需要仔细追踪输入图中的块对应于输出图中的像素(和他的相对应的敏感性图),但是等式12可以在MATLAB中使用基于重叠的valid区域进行卷积得到,只需要一行代码:
与其进行逐元素相乘。乍一看,我们可能需要仔细追踪输入图中的块对应于输出图中的像素(和他的相对应的敏感性图),但是等式12可以在MATLAB中使用基于重叠的valid区域进行卷积得到,只需要一行代码:
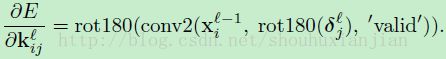 (公式13)
(公式13)
这里我们旋转图的目的是为了执行交叉关联而不是卷积,将输出旋转回来是为了当在前馈中执行卷积的时候,这个核可以得到期望的方向。
3.2 子采样层
一个子采样层可以生成输入图的下采样版本。如果有 N 个输入图,那么就会有N 个输出图,虽然输出图可能会变得很小。但是正式的说:
 (公式14)
(公式14)
这里down(·)表示一个子采样函数。通常这个函数会将输入图像中每个不同的 n×n的块上执行加操作,这样这个输出图像在时空维度上就是原来的1/n 了。每个输出图都有自己相对应的乘法偏置和一个额外的偏置b。我们可以简单的抛开图中的其他样本(脚注部分:Patrice Simard的“pulling”和“pushing”当你使用0填充的conv去计算敏感性和梯度的时候是不需要的)。
3.2.1 计算梯度
这里的困难在于计算敏感性图。当我们做到了这步的时候,当需要更新的唯一可以学习的参数是偏置参数和b 。我们假设这个子采样层的上面和下面都由卷积层包围了。如果跟随着子采样层的是一个全连接层,那么关于这个子采样层的敏感性图可以通过部分2中描述的 BP算法来进行计算。
当我们试图计算在部分3.1.1中的核梯度的时候,我们不得不指出在给定输出图中的像素并找出输入中相对应的块。在这里,我们必须指出在给定下一层的敏感性图中的像素的时候指出当前层的敏感性图中对应的块,以便应用一个和等式5看上去差不多的delta递归。当然,在输入块和输出像素之间的连接上相乘的权重是(旋转)卷积核的权重。这也可以用一行代码高效的执行卷积:
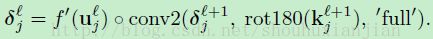
像以前一样,我们旋转这个核来使得卷积函数执行交叉关联。注意到在这个情况中,我们需要“full”卷积边缘处理,借助于MATLAB的命名法。这微小的不同让我们可以很轻松和高效的处理边缘的情况,输入到层+1中一个单元的数量不是完整的n×n大小的卷积核。这些情况下这个“full”卷积会将丢失的输入部分自动补0。
在我们已经准备好计算和 b 的梯度下,这个额外的偏置同样是通过对敏感性图中的元素进行累加得到的:
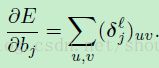
这里的乘法偏置当然包含了在前馈过程中计算的当前层上的原始下采样图。因为这个原因,在前馈计算中保存这些图也是很有必要的,所以我们不需要在BP中重新计算他们,这里我们定义:
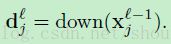
的梯度由下面的式子给出:
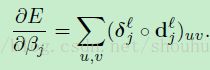
3.3 学习特征图的组合
很多时候,提供一个包含着在几个不同输入图上的卷积的和的输出图是很有优势的。在文献中,输入图是通过组合去形成一个手动选择的输出图的。然而,我们试图去在训练过程中学习这样的组合。让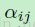 表示成在需要形成输出图j 的时候与输入图 i 之间的权衡宗。然后输出入可以通过下面的式子给出:
表示成在需要形成输出图j 的时候与输入图 i 之间的权衡宗。然后输出入可以通过下面的式子给出:
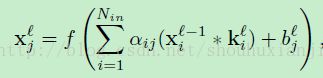
受限条件是:
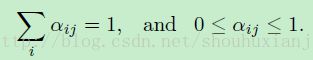
这些受限条件可以通过设置变量等于基于无约束,潜在权重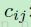
的softmax来实现:
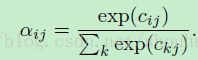
因为在指定 j 的权重的每个集合都是关于其他 j 的集合独立的,我们可以考虑在单一图上的更新和丢弃下标j 的情况 。每个图都以同样的方式更新,除了具有不同 j 指数的图。
softmax函数的偏导等于:
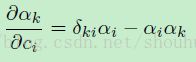 (公式15)
(公式15)
(这里采用的也是Kronecker delta),而在等式2中关于层上的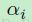 变量的偏导是:
变量的偏导是:
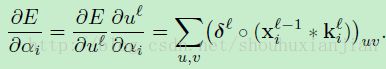
这里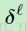 是敏感性图就相当于输出图的输入 u 。再一次,这里的卷积是“valid”的,这样这个结果才能匹配敏感性图的尺寸。现在我们能使用这个链式法则去计算损失函数(2)关于潜在权重
是敏感性图就相当于输出图的输入 u 。再一次,这里的卷积是“valid”的,这样这个结果才能匹配敏感性图的尺寸。现在我们能使用这个链式法则去计算损失函数(2)关于潜在权重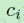 的梯度:
的梯度:
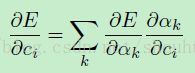 (公式16)
(公式16)
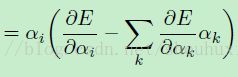 (公式17)
(公式17)
3.3.1 采用稀疏组合
我们同样试图去在给定一个图的基础上在权重 的分布上加上稀疏约束,通过添加正则化惩罚项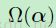 到最终的损失函数上。这样的好处是可以使得权重中的某些值呈现趋于0的情况。这样就只有很少的输入图会贡献到一个给定的输出图中。在单个样本上的损失图下:
到最终的损失函数上。这样的好处是可以使得权重中的某些值呈现趋于0的情况。这样就只有很少的输入图会贡献到一个给定的输出图中。在单个样本上的损失图下:
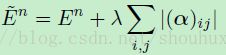 (公式18)
(公式18)
并发现了正则化项到权重梯度的贡献.这个用户自定义的参数 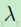 控制着在训练数据上这个网络的最小化拟合的程度,并且确保在正则化项中提到的权重是按照1-范数 小型化的。我们再次考虑在给定输出图的权重和丢弃下标 j 的情况。首先,我们需要:
控制着在训练数据上这个网络的最小化拟合的程度,并且确保在正则化项中提到的权重是按照1-范数 小型化的。我们再次考虑在给定输出图的权重和丢弃下标 j 的情况。首先,我们需要:
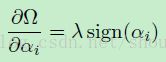 (公式19)
(公式19)
在任何除了起始的地方。将这个结果与公式15相结合可以然我们得到这个贡献:
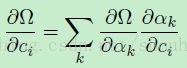 (公式20)
(公式20)
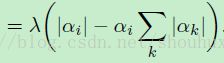 (公式21)
(公式21)
当使用这个惩罚损失函数(公式18)的时候,权重最终的梯度可以使用公式20和16计算:
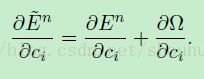
3.4 在Matlab中的加速
在一个子采样和卷积层相互交替的网络中主要的计算瓶颈是:
- 在前馈中:下采样卷积层的输出图
- 在BP中:更高子采样层delta的上采样去匹配更低卷积层输出图的尺寸
- sigmoid的应用和他的偏导
当然在前馈和BP阶段中卷积的计算也是瓶颈,但是假设这个2D卷积程序是高效执行的,那么这部分也就没什么可以优化的了。
然而,还是需要去试图使用MATLAB内建的图像处理程序去处理上采样和下采样操作。对于上采样,imresize可以做这个工作,但是会有明显的开销。
一个更块的替代方法是使用Kronecker积函数kron,来处理矩阵上采用,这个可以不同数量级的加速。当在前馈中的下采样过程中,imresize不提供关于下采样的选择,只是将不同的n×n块进行求和罢了。“
最近邻”方法可以用块中的一个原始像素来替换整块像素。一个可选方法是用blkproc在每个不同的块上进行操作,或者将im2col和colfilt组合起来。这些操作都只是计算需要的部分而没有其他的开销,重复的调用用户自定义的块-预处理函数会明显的过多的开销。一个更快速的方法是用矩阵来对图像进行卷积,然后简单的对其他条目进行标准索引(例如:
y = x(1:2:end,1:2:end))。
尽管在这个案例中卷积实际计算了四次和我们需要的输出一样多(假设是2x的下采样),这种方法仍然(实验性的)比之前提到的方法要快。
大多数作者执行sigmiod激活函数和他的偏导的时候都是使用inline函数定义的。但是在MATLAB中“inline”的定义和C中晚期不同,而且还需要大量的时间去评估,因此通常来说是用实际的代码进行替换的。这也是对于代码优化和可读性之间的权衡问题。
4 实际训练问题(不完整)
4.1 批量更新VS在线更新
批量学习VS随机梯度下降
4.2 学习率
LeCun的随机在线方法(diagonal approx to hessian),这值得吗?Viren的观点是:至少对于每层来说有不同的学习率,因为更低层的梯度更小而且更不可靠。LeCun的观点相似于【5】中说的。
4.3 损失函数的选择
误差平方(MLE)VS交叉熵 (cross-entropy)。后者在很多分类任务上比前者好。
4.4 检查求导是否正确
有限微分是当需要验证写的BP执行(求导)代码是否正确的不可缺少的工具(就是UFLDL中每个任务都需要进行cost函数验证的部分)。BP() 或者求导写的代码不但容易犯错而且仍然是个需要学习某些东西的网络(这句可忽略)通过检查写的代码的梯度导数是可以验证是否写错了的好方法。对于一个输入样本来说,使用二阶有限微分来验证梯度:
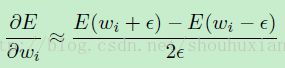
还需要检查BP代码的梯度返回值。Epsilon应该尽可能的小,但是不要太小而引起数值精度问题。例如=10e-8,都还好。注意到使用有限微分去训练网络通畅是低效的(即有在基于W权重上有O(W^2)的时间复杂度);但是 O(W) 带来的 BP 的速度优势还是值得应对这些麻烦的。
以上是 Notes on Convolutional Neural Networks 中文翻译 的全部内容, 来源链接: utcz.com/z/264708.html