MySQL 事务之 redo log
事务的原子性、隔离性、一致性、持久性这些就不在这里介绍了。InnoDB引擎支持事务而MyISAM不支持。MySQL中事务的自动提交默认是开启的,也就是如果我们不显式开启事务,那么每条语句就默认算是一个独立的事务。接下来重点介绍redo日志。
之前 Buffer Pool 的时候说过,当对数据页进行修改之后,不是立即刷新到磁盘,而是先存在Buffer Pool里的,而事务又需要保证持久性,也就是即使发生了崩溃,这些更改也不会丢失。因此为了满足持久性的要求,同时考虑性能(不能粗暴的每次提交事务就将Buffer Pool上修改的页刷新到磁盘),MySQL设计了redo日志(redo log),思想就是在事务提交时,将每次对具体页面的具体内容的改动点同步到磁盘上,这样每次需要同步到磁盘的内容就很小,也保证了事务的持久性,崩溃之后可以按照redo日志来恢复改动点。
redo 日志格式
redo 日志的格式比较复杂,就不在这里介绍了,简单理解一下思想就行。简单的 redo 日志像这样:
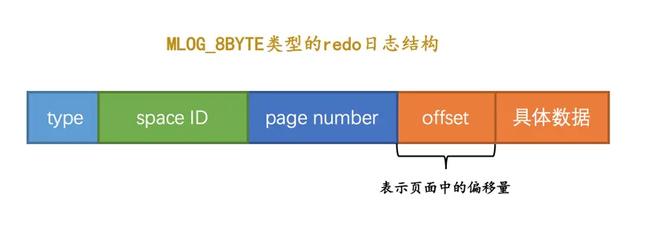
通过上面这条 redo 日志可以直接定位到某个页的偏移量的具体修改内容。
但上面这种只是最简单的情况。有些时候我们修改一个数据可能会修改非常多的地方,比如聚簇索引、B+ 树二级索引的页面,并且有可能既要更新叶子节点页面,也要更新非叶子节点页面,也有可能进行页分裂创建新的页面。除此之外,还有什么 File Header、Page Header、Page Directory 等等部分需要更新(可以回忆一下之前数据页结构的部分),也就是一个页面中也会有很多地方的改动,像这样:
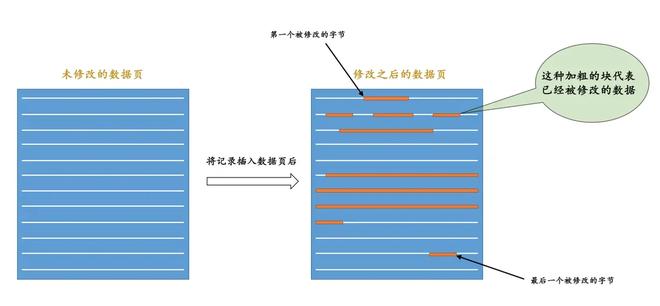
因此在这种情况下,如果每个具体的修改内容都用一条redo日志来表示,那redo日志占用的空间也会挺大的,所以这种情况下MySQL又用的是另一种比较复杂的redo日志来记录。具体的redo日志格式就不看了,思想就是对于一个页面中的多处改动,不会具体记录每个地方的改动,而是记录产生这些改动的必要信息(相当于只是从逻辑层面上记录,而没有在物理层面上记录,只能用一定逻辑恢复,而不能直接依赖这些redo日志恢复页面)。之后需要恢复时,MySQL会调用相应的函数,读取这些redo日志对相应的页面进行恢复。
有些操作会产生多条 redo 日志,并且还需要保证是原子的,比如在B+树二级索引中插入一条记录,可能会产生很多条redo日志(比如页分裂的情况),为了保证原子性,多条redo日志会以组的形式记录,在这组redo日志后面会加上一条特殊类型的redo日志,表示前面是一组完整的redo日志。如果是单个日志,在日志的type字段里会有一个比特位来表示是一条单一的redo日志。
对底层页面中的一次原子访问的过程称为一个Mini-Transaction,一个Mini-Transaction可以包含一组redo日志。
redo 日志的写入过程
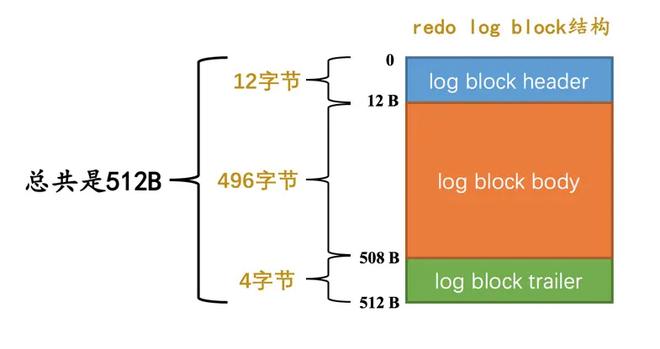
类似 MySQL 的一条记录是存储在数据页中,redo 日志也是存储在一个大小为 512 byte 的 block 中,叫做 redo log block,其中,redo 日志存储在 log block body 中:
类似 Buffer Pool,redo日志也是先写入一个缓冲区,之后再刷到磁盘,叫做 redo log buffer,是一片连续的内存空间:
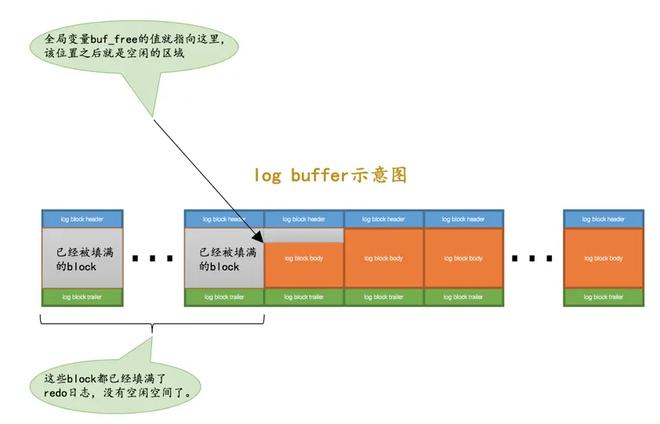
redo 日志写入 log buffer 是顺序写入的,一个 Mini-Transaction 对应的一组redo日志会在这个Mini-Transaction结束之后整体写入log buffer。而redo log buffer在一些时机下会刷新到磁盘:
- 写入的redo log超过一定容量时
- 事务提交时会刷一次,为了保证事务的持久性
- 后台线程定时刷
- 其他时机
全局变量buf_free标记了当前redo日志写到的位置,还有一个全局变量buf_next_to_write标记了下一个需要刷新到磁盘的redo日志的位置(buf_next_to_write前面的redo日志都已经刷新到磁盘)。
Log Sequence Number
Log Sequence Number翻译过来就是日志序列号,简称LSN,是用来记录已经产生的redo日志量的一个全局变量。具体地说,LSN是按照产生的redo日志的字节数增长的(还要加上写入的redo日志占用的log block header和log block trailer的字节数)。
LSN的初始值是8704,系统启动初始化时,LSN变为8704+12=8716,因为redo日志是从log block body开始写入的,前面的log block header占了12字节。当开始写入redo日志后,LSN根据写入redo日志的字节数增加,增长的量就是生成的redo日志占用的字节数加上额外占用的log block header和log block trailer的字节数。
因此可以看出,每个redo日志都有一个唯一的LSN与其对应,LSN值越小,说明redo日志产生的越早。
除了LSN之外,还有一个全局变量叫flushed_to_disk_lsn,记录已经刷新到磁盘的redo日志的LSN。
之前讲Buffer Pool的时候提到过flush链表。当某个缓存在Buffer Pool的页第一次被修改的时候就会被放入flush链表,同时会将修改该页面的Mini-Transaction开始时的LSN值写入该页面的控制块(回忆Buffer Pool的结构,每个缓存页都有一个控制块)中的oldest_modification字段。当这个页之后被修改时,不会重新插入flush链表,但会将最新一次修改的Mini-Transaction结束时的LSN值写入该页面的控制块的newest_modification字段。也就是flush链表可以看成是按照oldest_modification排序的。
Checkpoint
redo 日志在磁盘上也是存储在文件里的,存放在一个个以ib_logfile[数字]命名的文件中,像这样:
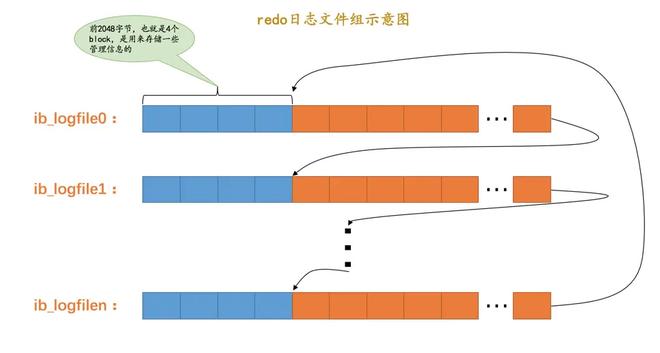
整个 redo 日志文件组是循环使用的,如果最后一个文件也写满了,那就从头开始写。这样就有可能造成将之前的redo日志覆盖掉的情况。然而,只有那些对应的脏页已经同步到磁盘上的redo日志,才可以被覆盖。因此,MySQL 使用一个全局变量checkpoint_lsn来标记对应的脏页已经刷新到磁盘的redo日志的LSN。
当 flush 链表中的页被同步到了磁盘,这个脏页就会从flush链表中被移除,checkpoint_lsn就会变为flush链表中的第一个页的oldest_modification值,因为在这个oldest_modification值之前的LSN一定都是被同步到了磁盘的。计算出checkpoint_lsn之后,MySQL会再计算一些checkpoint信息(checkpoint_no,checkpoint_offset),然后一起存到redo日志文件组的第一个日志文件的管理信息中。
简单说一下,checkpoint_lsn 和 flushed_to_disk_lsn 完全不是一个东西,前者标记的是脏页有多少被刷到了磁盘,后者标记的是 redo 日志有多少被刷到了磁盘,这两个东西都是需要记录的
崩溃恢复
redo日志在一般情况下都没什么用,但如果服务器真的崩溃了,那它就很关键,可以帮助我们将页面恢复到崩溃前的状态。接下来大概看一下MySQL是如何根据redo日志来恢复页面的。
首先确定恢复的起点,也就是从哪个LSN开始恢复。这个起点就是上面的checkpoint_lsn,因为 checkpoint_lsn 之前的redo日志对应的页面修改一定都是被刷到磁盘了的。
之后确定恢复的终点,其实就是从起点一直往后找到一个没有写满的redo log block,那么它就是此次恢复中的最后一个block。
在恢复的过程中,MySQL 也有一些小优化:
- 同一个页的 redo 日志按照修改顺序放到一个链表中,之后一次性将页面修改好,避免了随机IO
- 跳过已经刷新到磁盘的页面。最开始讲数据页结构的时候看到每个页面的 File Header 里都有一个
FIL_PAGE_LSN的属性,记录了最近一次修改页面时的LSN值,因此可以判断出某个LSN对应的修改是否已经同步到磁盘上了。
以上是 MySQL 事务之 redo log 的全部内容, 来源链接: utcz.com/z/264463.html