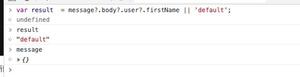
Elasticsearch Painless从嵌套元素计算分数
注意: 我最初发布此问题的方式有所不同,因此不值得更新,因为阅读后我学到了更多。
回答:
搜索文档并根据文档中的嵌套元素计算自定义分数。
回答:
{ "mappings": {
"book": {
"properties": {
"title": { "type": "string", "index": "not_analyzed" },
"topics": {
"type": "nested",
"properties": {
"title": { "type": "string", "index": "not_analyzed" },
"weight": { "type": "int" }
}
}
}
}
}
}
回答:
{ "query": {
"function_score": {
"query": {
"term": { "title": "The Magical World of Spittle" }
},
"script_score": {
"script": {
"lang": "painless",
"inline": "int score = 0; for(int i = 0; i < doc['topics'].values.length; i++) { score += doc['topics'][i].weight; } return score;",
"params": {
"default_return_value": 100
}
}
}
}
}
}
回答:
int score = 0;for(int i = 0; i < doc['topics'].values.length; i++) {
score += doc['topics'][i].weight;
}
return score;
回答:
在类型[book]的映射中找不到[topics]的字段
回答:
- 怎么了?
- 该怎么办?
回答:
嵌套文档存储在索引中的不同文档中,因此您不能通过父文档中的doc值来访问它们。您需要使用源文档并导航至topics.weight属性,如下所示:
孤立无痛:
int score = 0; for(int i = 0; i < params._source['topics'].size(); i++) {
score += params._source['topics'][i].weight;
}
return score;
完整查询:
{ "query": {
"function_score": {
"query": {
"term": { "title": "Book 1" }
},
"script_score": {
"script": {
"lang": "painless",
"inline": "int score = 0; for(int i = 0; i < params._source['topics'].size(); i++) { score += params._source['topics'][i].weight; } return score;",
"params": {
"default_return_value": 100
}
}
}
}
}
}
PS:还请注意,该类型int不存在,它是integer
以上是 Elasticsearch Painless从嵌套元素计算分数 的全部内容, 来源链接: utcz.com/qa/424410.html