crapy管道以正确的格式导出csv文件
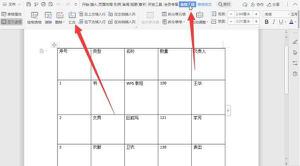
从前,我偶然发现了这个问题。如果您使用的是macOS,请转至Macintosh HD>应用程序> Python3.6文件夹(或您使用的任何Python版本)>双击“ Install Certificates.command”文件。我根据下面alexce的建议进行了改进。我需要的是下面的图片。但是,每一行/每一行都应该是一个评论:带有日期,评分,评论文字和链接。
我需要让项目处理器处理每个页面的每个评论。
当前,TakeFirst()仅对页面进行第一次审核。所以10页,我只有10行/行,如下图所示。
spider代码如下:
import scrapyfrom amazon.items import AmazonItem
class AmazonSpider(scrapy.Spider):
name = "amazon"
allowed_domains = ['amazon.co.uk']
start_urls = [
'http://www.amazon.co.uk/product-reviews/B0042EU3A2/'.format(page) for page in xrange(1,114)
]
def parse(self, response):
for sel in response.xpath('//*[@id="productReviews"]//tr/td[1]'):
item = AmazonItem()
item['rating'] = sel.xpath('div/div[2]/span[1]/span/@title').extract()
item['date'] = sel.xpath('div/div[2]/span[2]/nobr/text()').extract()
item['review'] = sel.xpath('div/div[6]/text()').extract()
item['link'] = sel.xpath('div/div[7]/div[2]/div/div[1]/span[3]/a/@href').extract()
yield item
回答:
我从头开始,下面的spider应该与
scrapy crawl amazon -t csv -o Amazon.csv --loglevel=INFO
因此,使用电子表格打开CSV文件对我来说是
希望这可以帮助 :
import scrapyclass AmazonItem(scrapy.Item):
rating = scrapy.Field()
date = scrapy.Field()
review = scrapy.Field()
link = scrapy.Field()
class AmazonSpider(scrapy.Spider):
name = "amazon"
allowed_domains = ['amazon.co.uk']
start_urls = ['http://www.amazon.co.uk/product-reviews/B0042EU3A2/' ]
def parse(self, response):
for sel in response.xpath('//table[@id="productReviews"]//tr/td/div'):
item = AmazonItem()
item['rating'] = sel.xpath('./div/span/span/span/text()').extract()
item['date'] = sel.xpath('./div/span/nobr/text()').extract()
item['review'] = sel.xpath('./div[@class="reviewText"]/text()').extract()
item['link'] = sel.xpath('.//a[contains(.,"Permalink")]/@href').extract()
yield item
xpath_Next_Page = './/table[@id="productReviews"]/following::*//span[@class="paging"]/a[contains(.,"Next")]/@href'
if response.xpath(xpath_Next_Page):
url_Next_Page = response.xpath(xpath_Next_Page).extract()[0]
request = scrapy.Request(url_Next_Page, callback=self.parse)
yield request
以上是 crapy管道以正确的格式导出csv文件 的全部内容, 来源链接: utcz.com/qa/408164.html