在每个GROUP BY组中选择第一行?
如标题所示,我想选择以分组的每组行的第一行GROUP BY。
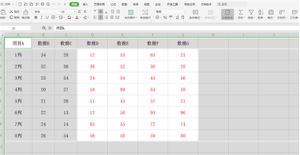
具体来说,如果我有一个purchases看起来像这样的表:
SELECT * FROM purchases;我的输出:
id | customer | total---+----------+------
1 | Joe | 5
2 | Sally | 3
3 | Joe | 2
4 | Sally | 1
我想查询每个人id最大的购买金额(total)customer。像这样的东西:
SELECT FIRST(id), customer, FIRST(total)FROM purchases
GROUP BY customer
ORDER BY total DESC;
Expected Output:
FIRST(id) | customer | FIRST(total)----------+----------+-------------
1 | Joe | 5
2 | Sally | 3
回答:
在PostgreSQL中,这通常更简单,更快捷(下面将进行更多性能优化):
SELECT DISTINCT ON (customer) id, customer, total
FROM purchases
ORDER BY customer, total DESC, id;
或更短(如果不太清楚),输出列的序号为:
SELECT DISTINCT ON (2) id, customer, total
FROM purchases
ORDER BY 2, 3 DESC, 1;
如果total可以为NULL(无论哪种方式都没有问题,但是您需要匹配现有索引):
...ORDER BY customer, total DESC NULLS LAST, id;
DISTINCT ON是标准的PostgreSQL扩展(仅DISTINCT在整个SELECT列表中定义)。
在DISTINCT ON子句中列出任意数量的表达式,合并的行值定义重复项。手册:
显然,如果两行至少有一个列值不同,则认为它们是不同的。在此比较中,将空值视为相等。
DISTINCT ON可以结合使用ORDER BY。中的前导表达式ORDER BY必须在中的表达式集中DISTINCT ON,但是您可以在这些表达式之间自由地重新排列顺序。例子。
您可以添加其他表达式以ORDER BY从每个对等组中选择特定的行。或者,如手册所述:
的DISTINCT ON表达式(一个或多个)必须最左边的匹配ORDER BY 表达式(一个或多个)。该ORDER BY子句通常将包含其他表达式,这些表达式确定每个DISTINCT ON组中行的期望优先级。
我添加id了最后一个打破联系的项目:
“id从各组中共享最小的组中选择最小的行total。”
要以与确定每个组第一个的排序顺序不同的方式对结果进行排序,可以将上面的查询嵌套在另一个外部查询中ORDER BY。例子。
如果total可以为NULL,则您很可能希望具有最大非空值的行。加NULLS LAST样演示。看:
按ASC列排序,但先使用NULL值?
该SELECT列表不受表达式以任何方式DISTINCT ON或ORDER BY任何方式的约束。(在上面的简单情况下不需要):
您不必在DISTINCT ON或中包含任何表达式ORDER BY。
您可以在SELECT列表中包括任何其他表达式。这有助于用子查询和聚合/窗口函数替换更复杂的查询。
我使用Postgres 8.3 – 13版进行了测试。但是至少从7.1版开始,该功能就一直存在,因此基本上总是如此。
指数
上面查询的理想索引是一个多列索引,它以匹配顺序和匹配的排序顺序跨越所有三列:
CREATE INDEX purchases_3c_idx ON purchases (customer, total DESC, id);可能太专业了。但是,如果特定查询的读取性能至关重要,请使用它。如果您DESC NULLS LAST在查询中,请在索引中使用相同的索引,以便排序顺序匹配并且索引适用。
在为每个查询创建量身定制的索引之前,请权衡成本和收益。上述指标的潜力在很大程度上取决于数据分布。
使用索引是因为它提供了预排序的数据。在Postgres 9.2或更高版本中,如果索引小于基础表,则查询也可以从仅索引扫描中受益。但是,必须完整扫描索引。
对于每个客户几行(列中的基数很高customer),这是非常有效的。如果您仍然需要排序的输出,则更是如此。随着每个客户行数的增加,收益也随之减少。
理想情况下,您有足够的work_mem能力在RAM中处理相关的排序步骤,而不会溢出到磁盘上。但是通常设置work_mem 得太高会产生不利影响。考虑SET LOCAL进行特别大的查询。使用查找您的需求EXPLAIN ANALYZE。
以上是 在每个GROUP BY组中选择第一行? 的全部内容, 来源链接: utcz.com/qa/399929.html