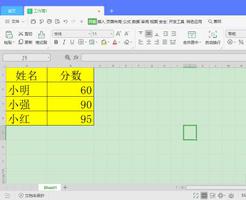
R-获取documenttermmatrix中每个文档的标记计数
我想这样做的原因是我可以将绝对频率转换为相对频率。对于每个文档都很容易获得令牌计数,但我不确定如何获取每个文档的总令牌计数并同时使用它,因此我可以同时对每个文档执行/总令牌计数,有没有什么方法可以绑定rowsums,然后使用计算中的列,如果这是正确的方法来做到这一点?R-获取documenttermmatrix中每个文档的标记计数
感谢
回答:
从英文版本的heliohost corpus为我的文字数据的利用博客的数据,这是很容易通过quanteda包度日文件标记计数。
library(readr) library(quanteda)
blogFile <- "./capstone/data/en_US.blogs.txt"
inFile <- blogFile
blogData <- read_lines(blogFile)
system.time(theText <- corpus(blogData))
head(summary(theText))
...和输出是:
> head(summary(theText)) Corpus consisting of 899288 documents, showing 100 documents:
Text Types Tokens Sentences
text1 18 20 1
text2 6 7 1
text3 104 154 7
text4 36 43 1
text5 91 119 5
text6 13 13 1
Source: C:/Users/leona/gitrepos/datascience/* on x86-64 by leona
Created: Sat Dec 02 20:59:23 2017
Notes:
>
回答:
谢谢。实际上,我想我找到了一种方法,用rowSums(dtm)来划分。我希望这是正确的方法。
以上是 R-获取documenttermmatrix中每个文档的标记计数 的全部内容, 来源链接: utcz.com/qa/259120.html