Java大数据快速精确匹配?
问题描述
从一个存储介质(可以是List,Map,redis,DB)里面有约20万-50万行左右的记录(可以理解为每行1个词),现在需要从一句话中快速匹配这句话中是否有词库记录。
问题出现的环境背景
用于聊天场景中对定向词库的判断。比如提供一句话如:“我爱北京天安门,天安门前有人民英雄纪念碑,我希望去哪里看一看”。如果词库中有一条是“纪念碑”的话,则匹配成功。
因为内部数据,词库暂不能提供
你期待的结果是什么?
提供一个方法,传入一句话(一个字符串),如果包含词库内容,则返回该单词,如果未包含则返回NULL。
词库可以存在任意介质中(List,Map,redis,DB),这个主要取决于性能要求,性能最佳为最佳结果。方法有很多只取万花丛中效率最高的算法。
回答:
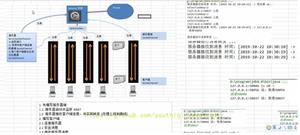
我认为比较好的并且简单的方法,是将所有的单词,拆分成单个字,然后做成一个用 HashMap 连接起来的字典,结构如下图:
之后句子只要循环一次,判断下一个字是否存在,如果存在继续往下找,如果不存在则终止,说明找到单词。
代码如下:
public class Test { static String[] sentences = {
"纪念碑", "纪念册", "天安门", "天气"
};
private static Map<String, Object> init(String[] sentences) {
Map<String, Object> map = new HashMap<>();
for (String sentence : sentences) {
String firstWord = sentence.substring(0, 1);
Map<String, Object> prevMap = (Map<String, Object>) map.computeIfAbsent(firstWord, s -> new HashMap<String, Object>());
for (int i = 1; i < sentence.length(); i++) {
String nextWord = sentence.substring(i, i + 1);
prevMap = (Map<String, Object>) prevMap.computeIfAbsent(nextWord, s -> new HashMap<String, Object>());
}
}
return map;
}
private static Set<String> detection(String sentence, Map<String, Object> map) {
Set<String> result = new HashSet<>();
Map<String, Object> deMap = map;
String singleWord = "";
for (int i = 0; i < sentence.length(); i++) {
String word = sentence.substring(i, i + 1);
if (deMap.containsKey(word)) {
singleWord += word;
Map<String, Object> o = (Map<String, Object>) deMap.get(word);
if (o.isEmpty()) {
result.add(singleWord);
singleWord = "";
deMap = map;
} else {
deMap = (Map<String, Object>) deMap.get(word);
}
} else if (!singleWord.isEmpty()) {
System.out.println("匹配中断,后移一位");
deMap = map;
i = i - singleWord.length();
singleWord = "";
}
}
return result;
}
public static void main(String[] args) {
Map<String, Object> map = init(sentences);
String sentence = "我爱北京天安门,天安门前有人民英雄纪念碑,我希望去哪里看一看";
Set<String> detection = detection(sentence, map);
System.out.println("检测到词语:" + detection);
}
}
补充一下覆盖的情况,例如 "你好" 和 "你好吗",如果句子中只含有你好,上面的代码是会中止的,不会匹配到 "你好",因此需要在 map 中加上 一个 key : "好_end",这样如果匹配到中间中止,就查一下是否含有最后一个字加上 "_end"。
回答:
我认为你这个问题,实际上可以通过分词来解决,将一句话自动分词,然后拿这些词语取查库,查到了就返回。分词的话可以借助开源分词器,比如jieba分词,word分词等等
以上是 Java大数据快速精确匹配? 的全部内容, 来源链接: utcz.com/p/944855.html