关于JavaNIO中的ByteBuffer与UTF-8字符编码的一点疑问
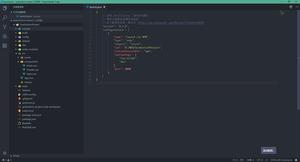
首先,show my code~(环境JDK8)
public static void main(String[] args) { //String => ByteBuffer
ByteBuffer byteBuffer1 = StandardCharsets.UTF_8.encode("qwer");
ByteBuffer byteBuffer2 = StandardCharsets.UTF_8.encode("哈");
ByteBuffer byteBuffer3 = StandardCharsets.UTF_8.encode("哈喽");
ByteBuffer byteBuffer4 = StandardCharsets.UTF_8.encode("为啥lim不等于cap呢?");
System.out.println("qwer" + byteBuffer1);
System.out.println("哈" + byteBuffer2);
System.out.println("哈喽" + byteBuffer3);
System.out.println("为啥lim不等于cap呢?" + byteBuffer4);
//ByteBuffer => String
System.out.println(StandardCharsets.UTF_8.decode(byteBuffer1));
System.out.println(StandardCharsets.UTF_8.decode(byteBuffer2));
System.out.println(StandardCharsets.UTF_8.decode(byteBuffer3));
System.out.println(StandardCharsets.UTF_8.decode(byteBuffer4));
}
控制台输出:
qwerjava.nio.HeapByteBuffer[pos=0 lim=4 cap=4]
哈java.nio.HeapByteBuffer[pos=0 lim=3 cap=3]
哈喽java.nio.HeapByteBuffer[pos=0 lim=6 cap=11]
为啥lim不等于cap呢?java.nio.HeapByteBuffer[pos=0 lim=27 cap=29]
qwer
哈
哈喽
为啥lim不等于cap呢?
疑问:为什么byteBuffer3和byteBuffer4的limit和cap不相同呢,而1 2的相同,还未读的时候不是应该相同吗?开始我以为是UTF8不定长的问题,研究了会儿发现想要读取值也必须要读全呀,有人知道是怎么回事吗?希望大佬解答一下~
更新:刚刚debug了一下,末端limit和cap之间都是0,这是为啥呀?
回答:
因为encode的时候,默认长度是字符串长度"abc" 这种,字符串长度和字节数一样的,直接够用"哈喽" 这种,字符串长度2,字节数6,编码过程中 buffer 长度不够,扩容规则是 n * 2 + 1 ,于是先扩容到 5,再扩容到 11
至于读取,因为有limit,是可以知道要读取多少的
以上是 关于JavaNIO中的ByteBuffer与UTF-8字符编码的一点疑问 的全部内容, 来源链接: utcz.com/p/944416.html