关于Mysql的join连接算法Block Nested-Loop Join算法是如何实现优化的?
以这篇博文为例
https://blog.csdn.net/wanbin6...
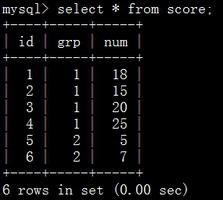
BNL算法原理:将外层循环的行/结果集存入join buffer,内存循环的每一行数据与整个buffer中的记录做比较,可以减少内层循环的扫描次数
举个简单的例子:外层循环结果集有1000行数据,使用NLJ算法需要扫描内层表1000次,但如果使用BNL算法,则先取出外层表结果集的100行存放到join buffer, 然后用内层表的每一行数据去和这100行结果集做比较,可以一次性与100行数据进行比较,这样内层表其实只需要循环1000/100=10次,减少了9/10。
======================
问题: joinbuffer中有10行数据,内层表的每一行与join_buufer中的数据做比较。比较此时是10*内层表的行数。
什么是“可以一次性与100行数据进行比较”
回答:
Simple Nested-Loop Join算法的缺点是对于内表的扫描次数太多,从而导致扫描的记录太过庞大。Block Nested-Loop Join算法较Simple Nested-Loop Join的改进就在于可以减少内表的扫描次数,甚至可以和Hash Join算法一样,仅需扫描内表一次。
Join Buffer会缓存所有参与查询的列而不是只有Join的列。
可以一次性与100行数据进行比较意思是可以批量比较。
以上是 关于Mysql的join连接算法Block Nested-Loop Join算法是如何实现优化的? 的全部内容, 来源链接: utcz.com/p/944270.html