python爬虫爬不到带有超链接的文本字段,需要怎么修改代码?
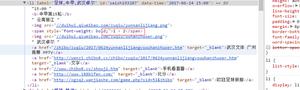
如下图,“绿色发展”这四个字由于在<p>标签中的a标签下爬不到正文中。网站上原句是 “一带一路”不仅是经济繁荣之路,也是绿色发展之路。 
但是我爬到的就是下图那样,到“也是”就停了,下一句又从“之路”开始,“绿色发展”这四个字就爬不到
查看网页结构如下图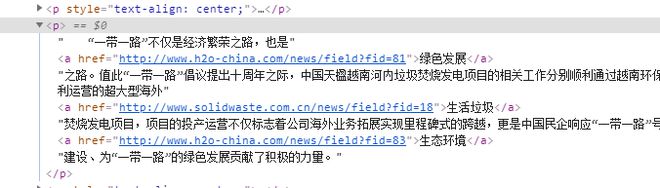
下面是我的xpath路径:
content = html.xpath('//div[@class="f14 l24 news_content mt25zoom"]/p/text()')
下面是我的全部代码,我需要怎样才能把带有超链接的文本段也爬到呢
import requestsfrom lxml import etree
import html
#爬取并转化为html格式
base_url="https://www.solidwaste.com.cn/news/342864.html"
resp=requests.get(url=base_url)
html = etree.HTML(resp.text)
#更换编码方式为网页对应的编码
encod = html.xpath('//meta[1]/@content')
if encod != []:
encod = encod[0].split("=")[1]
resp.encoding = encod
html = etree.HTML(resp.text)
#获取网页正文
content = html.xpath('//div[@class="f14 l24 news_content mt25 zoom"]/p/text()')
print(content)
content_deal=""
for i in content:
da = i.strip() + "\n"
# print(i.strip() + "\n", end="")
content_deal += da
print(content_deal)
回答:
先修改XPath路径以获取所有<p>标签下的所有节点(包括文本和标签):
content = html.xpath('//div[@class="f14 l24 news_content mt25 zoom"]/p//node()')然后在处理内容:
import requestsfrom lxml import etree
# 爬取并转化为html格式
base_url = "https://www.solidwaste.com.cn/news/342864.html"
resp = requests.get(url=base_url)
html = etree.HTML(resp.text)
# 更换编码方式为网页对应的编码
encod = html.xpath('//meta[1]/@content')
if encod != []:
encod = encod[0].split("=")[1]
resp.encoding = encod
html = etree.HTML(resp.text)
# 获取网页正文
content = html.xpath('//div[@class="f14 l24 news_content mt25 zoom"]/p//node()')
content_deal = ""
for node in content:
if isinstance(node, etree._ElementUnicodeResult):
content_deal += node.strip() + "\n"
elif isinstance(node, etree._Element) and node.tag == 'a':
content_deal += node.text.strip() + "\n"
print(content_deal)
以上是 python爬虫爬不到带有超链接的文本字段,需要怎么修改代码? 的全部内容, 来源链接: utcz.com/p/938842.html