有关线程的问题。
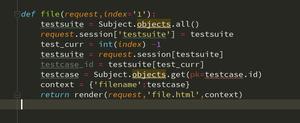
import threadingthread_lock = threading.RLock()
m = 0
def func(n):
# thread_lock.acquire()
global m
for i in range(n + 1):
m += i
print(m)
# thread_lock.release()
return
for i in range(2):
t = threading.Thread(target=func, args=(10000000, ))
t.start()
在没有用锁的情况下,最后打印的结果第一个是随机数,第二个是正确的数,即m经由func线程不断累加后的最终结果:'100000010000000'。我不懂的是,第二次遍历时为什么是正确的数?因为执行了第一次子线程后,全局变量m不也应该是在第一次的基础上继续累加吗?那这样一来第二次的数也应该不是正确的数才对啊?这里哪里有问题呢?
回答:
有锁,那么两个线程是顺序执行的,没啥可说的。
无锁,那么两个线程是交错执行的。第一个线程执行结束的时候,第二个线程也已经执行了一部分。所以结果是不确定的,因为第二个线程不一定执行了多少。也许第二个线程还会先结束。
因为执行了第一次子线程后,全局变量m不也应该是在第一次的基础上继续累加吗?那这样一来第二次的数也应该不是正确的数才对啊?这里哪里有问题呢?
听起来,你还是觉得“第二次”遍历在“第一次”遍历结束之后才发生。不是这样的。他们是一起遍历的。
这里还有一个问题,m += i 是原子的嘛?
其实,这里至少有三步操作:
- 读取 m
- 计算 m+i
- 将结果写入 m
所谓 m += i 是否是原子的,是说会不会有另一个线程的操作插入这三步之间。如果可以插入,它就不是原子的。那么两个线程的计算结果实际是不能保证的。
比如,m 原来是 0 ,两个线程各加一个 3 ,结果貌似应该是 6 。但是,在如下的流程下,结果是 3:
线程1 线程2读取m (0)
计算m+3 (3)
读取m (0)
计算m+3 (3)
写入m (3)
写入m (3)
只有保证 m += i 的原子性,才能保证最终结果是确定的。否则最终结果也是一个随机值。
m += i 是原子的吗?
python 并不保证它的原子性。而且,直到 python 3.9 ,它都确实不是原子的。
到了 python 3.10 ,因为一个偶然的原因,它变成了原子的。
(Python3.10 下为什么没有多线程自增安全问题了?)[https://segmentfault.com/q/10...]
所以用 3.10 测试,很可能总能在最后看到一个稳定的值。
但是,这是不可靠。也许到了 3.11 ,或者 3.10.13,它又不是原子的了。
回答:

很显然,使用线程锁在代码中等同于按顺序执行了线程的运行函数。
但是你出现的情况是未使用线程锁的情况第二次输出的数据为原本使用线程锁的最终结果。
这就需要考虑到运行环境的问题,我使用了32位的Python 3.10.4再进行测试(原本为64位的Python 3.9.2):
再对比一下两个Python版本的输出: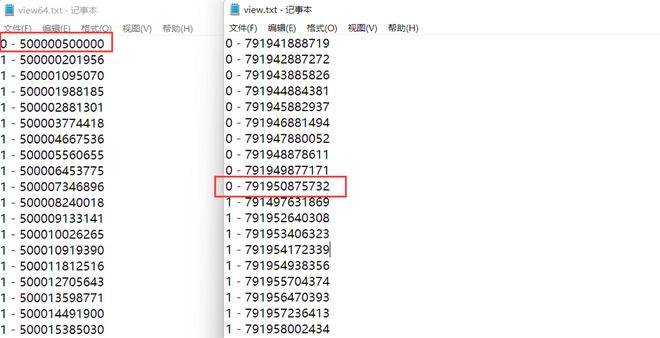
3.9.2 64位Python的线程1正好完成
正当我以为只是随机可能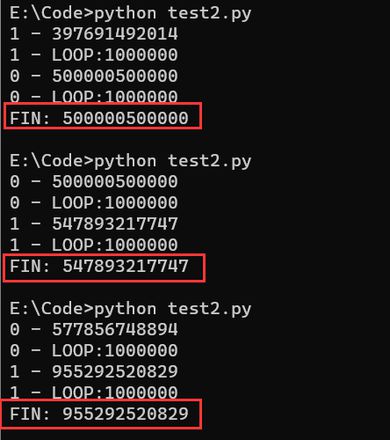
三次代码相同,其中一次正好输出结果十分的完美,且线程2率先完成。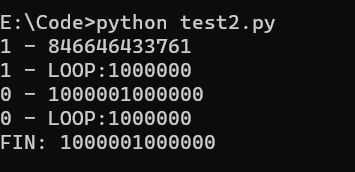
所以这场闹剧只是Python GIL锁的问题罢了(可能?)
如果换成多进程模块估计就不会出现这种事情了
以上是 有关线程的问题。 的全部内容, 来源链接: utcz.com/p/938529.html