求解答,解析几个m3u8地址了,报错了一个,找下是代码问题还是地址问题?

问题如下:
一个是可以解析的地址, https://1252524126.vod2.myqcloud.com/9764a7a5vodtransgzp1252524126/91c29aad5285890807164109582/drm/v.f146750.m3u8
一个是不能解析的地址,https://s7.fsvod1.com/20220703/BcqtmF44/1500kb/hls/index.m3u8
import urllib.request, urllib.error, requestsimport os, shutil
import re
from Crypto.Cipher import AES
url='https://s7.fsvod1.com/20220703/BcqtmF44/1500kb/hls/index.m3u8'
header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36'} # requests得到m3u8文件内容
content = requests.get(url, headers=header).text
print(content)
if "#EXTM3U" not in content:
print("这不是一个m3u8的视频链接!")
if "EXT-X-KEY" not in content:
print("没有加密")
# 使用re正则得到key和视频地址
jiami = re.findall('#EXT-X-KEY:(.*)\n', content)
# print(jiami[0],jiami)
key = re.findall('URI="(.*)"', jiami[0])
print(key)
# exit()
# vi = re.findall('IV=(.*)', jiami[0])[0]
# 得到每一个ts视频链接
tslist = re.findall('EXTINF:(.*),\n(.*)\n#', content)
print(tslist)
exit()
newlist = []
for i in tslist:
newlist.append(i[1])
# 得到key的链接并请求得到加密的kk
keyurl = key[0]
keycontent = requests.get(keyurl, headers=header).content
# 得到每一个完整视频的链接地址
base_url = url.replace(url.split('/')[-1], '')
# print(base_url)
tslisturl = []
for i in newlist:
tsurl = base_url + i
tslisturl.append(tsurl)
# 得到解密方法,这里要导入第三方库 pycrypto
# 这里有一个问题,安装pycrypto成功后,导入from Crypto.Cipher import AES报错
# 找到使用python环境的文件夹,在Lib文件夹下有一个 site-packages 文件夹,里面是我们环境安装的包。
# 找到一个crypto文件夹,打开可以看到 Cipher文件夹,此时我们将 crypto文件夹改为 Crypto 即可使用了
# 必须添加b'0000000000000000',防止报错ValueError: IV must be 16 bytes long
cryptor = AES.new(keycontent, AES.MODE_CBC, b'0000000000000000')
# for循环获取视频文件
for i in tslisturl:
print(i)
res = requests.get(i, header)
# 使用解密方法解密得到的视频文件
cont = cryptor.decrypt(res.content)
# 以追加的形式保存为mp4文件,mp4可以随意命名,这里命名为小鹅通视频下载测试
with open('小鹅通视频下载测试.mp4', 'ab+') as f:
f.write(cont)
回答:
(代码上传得稀烂。。。)
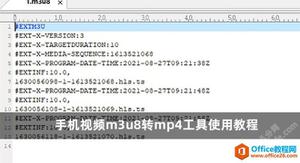
下载这两个文件之后用记事本打开即可发现一个是每一行都是一个ts文件的URL,另外一个是每一个ts切片文件URL行前都有一个解密的key文件
(我从来没有见过"v.f146750.m3u8"这个文件的格式,如果是你自己编出来的请按照"index.m3u8"这种标准m3u8文件的写法来编写m3u8解析的正则表达式)
所以对于"index.m3u8"这种解析需要
- 获取key
- 排除#开头的信息干扰(即在循环每一行中跳过"#"开头的行)
- 提取出ts文件路径
- 朝路径头加入域名信息
- 下载
- 解密
改进
对于m3u8文件的解密,推荐使用ffmpeg进行解密,在我本处下载安装pycrypto并且导入AES是没有问题的,如果你是使用IDLE(python自带的),请重新打开IDLE(否则其无法检测到打开后安装的模块)
使用循环下载ts文件是十分缓慢的,一个正常的视频也有几百个切片。在考虑到一些服务器的性能后推荐使用多线程进行下载。一部分服务器会在你大量下载ts文件后对你的IP黑名单几秒钟(而网页播放器为什么不会被黑名单我也不知道),需要写一个try-except的专门处理下载的函数进行循环获取。
否则如你的代码一样一旦某个请求被阻止,前面已下载的部分就前功尽弃了。
以上是 求解答,解析几个m3u8地址了,报错了一个,找下是代码问题还是地址问题? 的全部内容, 来源链接: utcz.com/p/938527.html