爬取网站的数据的问题?
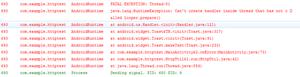
自己找了一个网站来练习爬虫,发现请求是成功的,就是获取不到网站的数据,后来,查看网页的js代码(如图):
发出在发送ajax 请求之前有一行代码 windows.open("","_bank")
现在,我用python 就没有办法去模拟这个点击打开一个新窗口的动作(如果没有,这个动作
接口是请求成功,但是,数据返回是一个空数组),求求大佬们给点意见(最好不要用selenium)
这是我写的代码
https://github.com/huchiwen/L...
回答:
跟这个没关系,空数组是因为两次请求的 cookie 没对上,get 搜索页也携带上 cookie 试试,我测试只需带上 PHPSESSID 即可
headers = { 'cookie': 'PHPSESSID=lr90bcpfbi2m431h2us7q8s41a'
}
回答:
window.open = console.logwindow.open(1)
把这个方法改写了。。。
以上是 爬取网站的数据的问题? 的全部内容, 来源链接: utcz.com/p/938510.html