python 按某行条件删除列
第1行数据已经根据大小进行了列排序
如果第0 行物质有重复(波长-列的index),则按左面的取,只保留一个波长列。 eg: CF2 只保留251.5, 删除271.0,259.0列
自己写的思路是先把1行非数字类型infoCol 去掉然后sort_values-> 转置以后在drop_duplicates(keep= 'first'), 也完成了想做的事情, 但最后还要再把infoCol 全拼回来感觉太复杂了,应该有更好的办法~~
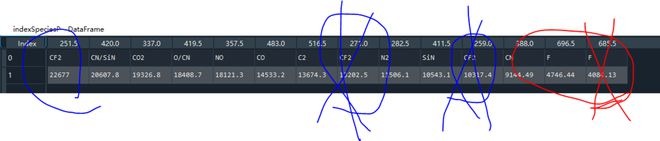
indexSpeciesP = indexSpecies[list(set(indexSpecies.columns).difference(infoCol))]#.iloc[0:2,:] indexSpeciesP = indexSpeciesP.sort_values(axis = 1, by = 1,ascending = False)
indexSpeciesP = indexSpeciesP.T.drop_duplicates(subset = [0],keep = 'first').T
indexSpeciesPP = pd.concat([indexSpecies[infoCol],indexSpeciesP], axis = 1)
原始数据是下面这种没经过排序的
如果第0行物质有重复,保留第一行数值大的那列,其他删掉,请问怎么写好一点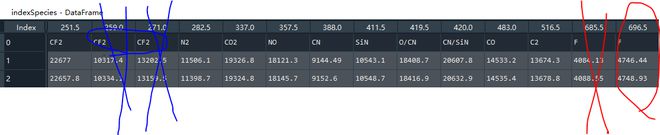
回答:
不用排序,一遍循环搞定
遍历数组,把数据放入到python的dict里面
dict的key是0行的内容,如:CF2,N2,CO2,CN,Sin,O/CN之类
value是一个两个元素的数组或者tuple也行,结构为[index行值,第1行以后的整列的值],如:[251.5,[22677,2657.8]]
循环遍历时,先找Key,找到key后,比较value的第一个元素index行值和当前遍历index行值,如当前遍历值小,continue。如果大,index行值和第1行以后的整列值整体覆盖Value
已参与了 SegmentFault 思否社区 10 周年「问答」打卡 ,欢迎正在阅读的你也加入。
回答:
如果是对原始数据进行过滤,其实就是2次分别遍历2行的过程(毕竟数据不多)
第一次对index=0和index=1两行的协同遍历,以index=1中数据较大的过滤保留index=0同名元素(对应索引值)
第二次,根据需要的索引值信息过滤index=3行数据。
因为不知道你原始数据构成机制,所以用为代码实现一下
fObj={}LIST0=LIST(index=0) #对应index=0的一行数据形成的列表
LIST1=LIST(index=1) #对应index=1的一行数据形成的列表
LIST2=LIST(index=2) #对应index=2的一行数据形成的列表
rtList0=[] #对应index=0的一行数据结果列表
rtList1=[] #对应index=0的一行数据结果列表
for i in range(len( LIST0 ) ): # 第一次循环
if fObj[ LIST0[i] ] == undifine :
fObj[LIST0[i]]=[LIST1[i],i] # 存储对应的LIST1行同位值,用于比较,并记录i
elif fObj[ LIST0[i] ][0]<LIST1[i] :
fObj[LIST0[i]]=[LIST1[i],i] # 因为新值更大而更新
for akey in fObj.keys(): # 第二次循环
rtList0.append( akey )
rtList1.append( LIST2[ fObj[akey][1] ] ) # 通过akey值查对应行中索引位置关系
注意,因为dict类型对数据存储排序关系是不稳定的,所以for akey in fObj.keys() 可能造成结果位置关系和原始关系不稳定,即虽然肯定结果是唯一关系,但不同的元素间排列顺序和原始数据比可能发生变化。
已参与了 SegmentFault 思否社区 10 周年「问答」打卡 ,欢迎正在阅读的你也加入。
以上是 python 按某行条件删除列 的全部内容, 来源链接: utcz.com/p/938455.html