aiohttp 为什么获取响应体要加 await

下面的代码来自 aiohttp 的官方:
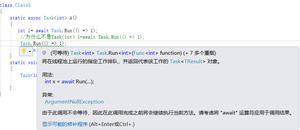
import aiohttpimport asyncio
async def main():
async with aiohttp.ClientSession() as session:
async with session.get('http://python.org') as response:
print("Status:", response.status)
print("Content-type:", response.headers['content-type'])
html = await response.text()
print("Body:", html[:15], "...")
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
为什么要获取 response.text() 需要加 await?按理来说既然 response.status 和 response.headers 都在了,那为什么 response.text() 还要等?
不考虑body很大以至于需要分片发送的场景,假设body只有 1 字节
回答:
请求的payload部分是StreamReader对象的子类,所以处理的时候必须await。
看了源码,响应过来的时候,按"\r\n"分割,一部分是响应头,一部分是body。header就直接做了解析,body被封装成了一个文件流对象
关于流的部分:https://docs.python.org/zh-cn...
以上是 aiohttp 为什么获取响应体要加 await 的全部内容, 来源链接: utcz.com/p/938297.html