HTTP 的 response 中的响应体和头部是分开发送的吗?
HTTP 报文的组成

Response 报文由:
- 状态行 start-line
- 响应头 HTTP headers
- 空行 empty-line
- 响应体 body
四部分组成
参考资料:
mozilla doc:Date
http里的时间格式
好了下面是问题的正文了
我发现一般的 HTTP 服务器在发送 Response 报文的时候,是把(状态行、响应头、空行)作为一个整体发送(即调用一次 socket.send()),然后在调用一次 socket.send() 把响应体 body 发出去。
看了 Gunicorn 服务器,和 aiohttp
为什么不一次发送呢?
下面是 Gunicorn 的两段源代码:
gunicorn/http/wsgi.py
def create(req, sock, client, server, cfg): resp = Response(req, sock, cfg)
environ = default_environ(req, sock, cfg)
# ...
environ['PATH_INFO'] = util.unquote_to_wsgi_str(path_info)
environ['SCRIPT_NAME'] = script_name
# ....
return resp, environ
class Response(object):
def start_response(self, status, headers, exc_info=None):
# ...
self.status = status
self.process_headers(headers)
return self.write
def write(self, arg):
self.send_headers() # 可以看到一句 self.send_headers(), 单独发出了 headers
# ...
util.write(self.sock, arg, self.chunked)
? 可以看到一句 self.send_headers(), 单独发出了 headers
gunicorn/util.py
def write(sock, data, chunked=False): if chunked:
return write_chunk(sock, data)
sock.sendall(data)
下面是一段 aiohttp 的 demo 代码。
import aiohttpimport asyncio
async def fetch(session, url):
async with session.get(url) as resp:
if resp.status != 200:
resp.raise_for_status()
data = await resp.text()
return data
? 比如 aiohttp 在获取 response.text 的时候会加一个 await,我不明白为什么要加 await ,因为客户端接收到 response 的时候,已经包含 text 了呀,为什么还要加一个 await 呢?除非是 text 是单独发送的,所以才会有 IO 等待的问题,是这样吗?
总结一下,问题的核心就是一般的 HTTP 服务器(nginx、 httpd、 tomcat、 uwsgi等等),在调用 socket 的 send 给 client 发送 HTTP response 的时候,是不是都是先调用一次 socket.send 发送不包含 body 的部分,在调用 N 次发送 body 的呢?
回答:
问题有点乱,我来逐一回答。
为什么不一次发送
socket实际上并不是直接发送的,而是发到buffer里的,接收也是从buffer里取。这个过程分为同步还是异步,如果是同步模式,buffer满了,则会阻塞,直到buffer有足够空间为止。如果是异步模式,则会返回一个错误标识符。buffer的发送是tcp传输层的事情,你个人是无法控制的.但在你看的这个代码的socket实际不是c语言里的socket,而是包装过的,分多次发送只是为了使业务逻辑更清晰,实际几次发送,怎么发送,得看操作系统实现的传输层协议的策略。
两次发送
这个纯粹是客户端的行为。
比如我们用的curl命令,底层是libcurl,当使用libcurl的POST方式时,假设POST数据的大小大于1024个字节,libcurl不会直接发送POST请求,而是会分为两步运行请求:
- 发送一个请求,该请求头部包括一个Expect: 100-continue的字段,用来询问server是否愿意接受数据
- 当接收到从server返回的100-continue的应答后,它才会真正的发起POST请求。将数据发送给server。
对于浏览器环境,如果是跨域请求,浏览器或先发送一个option请求,获取服务器的cors配置(在响应头里),你的请求符合服务器的cors策略,才会进一步发送正式的请求,否则就不会发送。
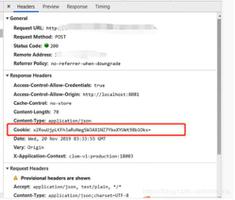
对于你说的304问题,以nginx为例,如果你请求一个静态文件的时候,nginx会给请求的实体生成一个唯一的etag,内存里会以etag为key,缓存的过期时间及请求大小等内容为value保存起来,并将对应的etag和expire返回给浏览器保存。后面再请求这个文件的时候,header带了对应的*Modified*等系列字段,那么nginx等服务端会用你带的这个字段的对应的值,跟它内存里缓存kv数据比较,如果符合缓存策略,则会直接返回304状态,这个时候body是空的。我这里是以nginx举例,你实际也可以自己实现,比如你请求/user/1,在你程序里,可以用这个地址的md5当做etag,过期时间当做expires返给客户端,当然还有date和cache-control。在redis里则存上以这个etag为key的缓存,下次请求的时候,如果header里带了If-Modified-Since和If-None-Match,那你直接解析出etag和过期时间跟redis里的数据对比,如果符合条件,则直接返回304状态,后面的逻辑不用走一遍了。
值得主要的是,上述的策略都是客户端和服务端的约定,你服务端可以接受,也可以不接受,并不是强制的。比如浏览器虽然带了Modified字段,但是我服务器不接受,也不缓存对应请求的对象的缓存信息,按普通请求跑一遍逻辑,返回200,也是正常的。只是说,如果服务器响应缓存策略,则可以减少服务端负担而已。
回答:
我记得以前响应头里面有个字段叫做页面生成时间,或许这个可以作为网页缓存
比如,浏览器收到响应头部分,发现网页修改时间没有变化,那么它可以直接读取缓存,就不继续接受body已节约流量请求
当然这只是我的想法
搜:Last-Modified 与 If-Modified-Since
以上是 HTTP 的 response 中的响应体和头部是分开发送的吗? 的全部内容, 来源链接: utcz.com/p/938285.html