[爬虫]关于新版花瓣网的max值问题
![[爬虫]关于新版花瓣网的max值问题](/wp-content/uploads/mrt/coding.jpg)
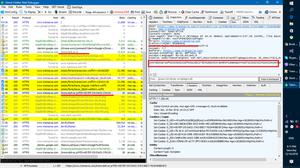
#在爬取花瓣网的过程中遇到获取max值的困难#第一页:https://api.huaban.com/boards/11867417/pins?limit=20?%ra=link
#第二页:https://api.huaban.com/boards/11867417/pins?max=1029389734&limit=20?%ra=link
#第三页:https://api.huaban.com/boards/11867417/pins?max=1014990899&limit=20?%ra=link
其中max值为前面一页的json里最后一个pin_id的值
现在的目的就是循环获取前面一页的最后一个pin_id值
然后加入到构造url中再次获取页面
https://api.huaban.com/boards/{num}/pins?+'max='+last_pin_id+'&'+'limit=20'
但不知道怎么弄
这是现在获取第一页的代码,能在此基础上实现吗
import reimport time
import json
import requests
import os
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
directory = input('---请输入您要创建的文件夹名---\n')
#文件夹
fileName = 'huabanimg\\'+directory+'\\'
if not os.path.exists(fileName):
os.makedirs(fileName)
#输入要抓取的花瓣boards
num = int(input('---请输入需要抓取的花瓣boards数字---\n'))
#网址
url = f'https://api.huaban.com/boards/{num}/pins?limit=20'
jsonData = requests.get(url,headers=headers)
text = jsonData.text
keySources = '"key":"(.*?)"'
keys = re.findall(keySources,text,re.S)
#循环获取key
for keyNum in range(len(keys)):
#拼接图片地址
imgUrl = 'https://hbimg.huabanimg.com/' + keys[keyNum] + '_fw658'
imgData = requests.get(imgUrl)
imgName = keys[keyNum][0:10]
print('正在提取第'+str(keyNum+1)+'张')
#保存图片
with open(fileName + imgName + '.jpeg','wb') as f:
f.write(imgData.content)
time.sleep(2)
以上是 [爬虫]关于新版花瓣网的max值问题 的全部内容, 来源链接: utcz.com/p/938270.html