pandas.read_csv()方法中`sep`和`delimiter`属性有什么区别?
sepstr, default ‘,’
Delimiter to use. If sep is None, the C engine cannot automatically detect the separator, but the Python parsing engine can, meaning the latter will be used and automatically detect the separator by Python’s builtin sniffer tool, csv.Sniffer. In addition, separators longer than 1 character and different from '\s+' will be interpreted as regular expressions and will also force the use of the Python parsing engine. Note that regex delimiters are prone to ignoring quoted data. Regex example: '\r\t'.
delimiterstr, default None
Alias for sep.
看了文献没有看懂。。。。。请指导
是不是sep,delimiter只能设置一个,优先使用sep作为分隔符,如果sep没有设置的话,则以delimiter作为分隔符?
回答:
看下源码呗,源码写的很清楚,这里是链接,能回答你的所有疑惑。
但还是给个建议,优先用 sep,因为它短(其实是因为一些其他方法中只能用 sep,就记这一个就行了)。
回答:
- delimiter是sep的别名,功能是一样的, 两者设置其中一个就可以了,如果同时设置,就会报错

- 设置sep=None, 就会有个告警,因为c engin不支持sep=None, 如果指定engin='python',就不会有告警
D:\Program Files (x86)\Python37-32\lib\site-packages\pandas\util\_decorators.py:311: ParserWarning: Falling back to the 'python' engine because the 'c' engine does not support sep=None with delim_whitespace=False; you can avoid this warning by specifying engine='python'.
return func(args, *kwargs)
我们设置engine=‘python’
另外,如果分隔符超过1个字符,就会被认为是正则,c引擎不支持,会强制使用python解析引擎,如果不指定引擎是python,就会给个告警
- delimiter和delim_whitespace这个参数有点关系
还有为啥还要为sep整个别名delimiter,这个源码文件中有解释
When a dialect is passed, it overrides any of the overlapping
# parameters passed in directly. We don't want to warn if the
# default parameters were passed in (since it probably means
# that the user didn't pass them in explicitly in the first place).
#
# "delimiter" is the annoying corner case because we alias it to
# "sep" before doing comparison to the dialect values later on.
# Thus, we need a flag to indicate that we need to "override"
# the comparison to dialect values by checking if default values
# for BOTH "delimiter" and "sep" were provided.
大致意思是说有个参数dialect,如果这个dialect参数赋值了,我们需要解析这个dialect,再解析这个dialect之前,需要有个flag来表明我们需要覆盖
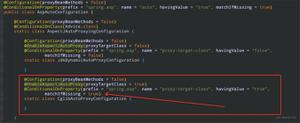
看下源代码,你应该会更清晰
if dialect is not None:kwds["sep_override"] = delimiter is None and (sep is lib.no_default or sep == delim_default
)
if delimiter and (sep is not lib.no_default):
raise ValueError("Specified a sep and a delimiter; you can only specify one.")if (
names is not Noneand names is not lib.no_default
and prefix is not None
and prefix is not lib.no_default
):
raise ValueError("Specified named and prefix; you can only specify one.")kwds["names"] = None if names is lib.no_default else names
kwds["prefix"] = None if prefix is lib.no_default else prefix# Alias sep -> delimiter.
if delimiter is None:delimiter = sepif delim_whitespace and (delimiter is not lib.no_default):
raise ValueError("Specified a delimiter with both sep and "
"delim_whitespace=True; you can only specify one."
)
if delimiter is lib.no_default:
# assign default separator valuekwds["delimiter"] = delim_default
else:
kwds["delimiter"] = delimiterif engine is not None:
kwds["engine_specified"] = Trueelse:
kwds["engine"] = "c"kwds["engine_specified"] = False
以上是 pandas.read_csv()方法中`sep`和`delimiter`属性有什么区别? 的全部内容, 来源链接: utcz.com/p/938203.html