批量读写 怎么提高mongo写入效率?

需要把一个库中的数据用脚本转化一下 写入到一些新的库中 大概有100w条
如果用for实在太慢了 看了一圈 如果要用多线程 都没有特别好的最佳实践
一般业内是怎么处理呢 ?
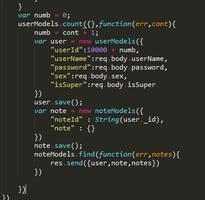
目前用的是最笨的办法:
i = coll.find({}):
for j in i:
parse(j)
new_coll.insert(parse(j))
其中主要的发现和瓶颈:
1、find那一步 是直接获取一个指针,但是100w的数据量 ,如果不加batch_size 会卡住。我现在设置batch为10,可以稳定提取,但是速度不够快
2、insert那一步,速度由find决定。显然如果用多线程会好一点。但是这个多线程是否会受find制约?
回答:
你现在的瓶颈是在写 MongoDB 上、还是你前面那个所谓的“转化”上?
如果是前者,MongoDB 本身是支持 bulkWrite 操作的;如果是后者,具体问题具体分析,信息太少猜不出来。
回答:
从你现在的描述来看,你需要充分利用 bulkWrite 特性来加速,并且在find中合理调整batch的大小到一个最高效率的度。
以上是 批量读写 怎么提高mongo写入效率? 的全部内容, 来源链接: utcz.com/p/938171.html