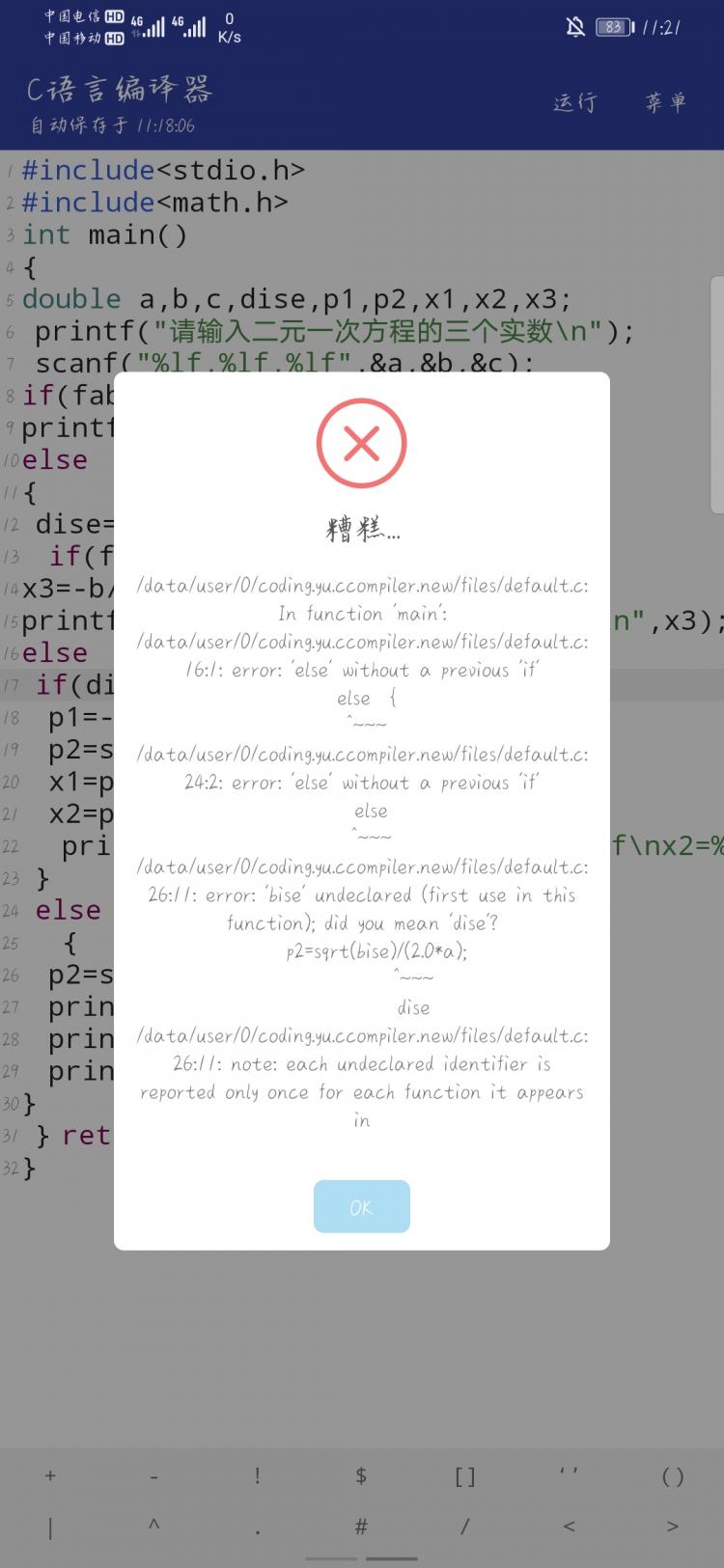
微博热搜是爬取不了吗?

微博热搜是爬取不了吗?我检查了热搜的网页代码也没变啊,就是莫名其妙爬不了,也没有报错~
import requests
from lxml import etree
import csv
from datetime import datetime
import time
import copy
def doSth():
try:
# 1.目标 url。
url = 'https://s.weibo.com/top/summary?cate=realtimehot'
# 模拟浏览器请求头
headers = {
'User-Agent': "Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50"}
# 2.发送请求
data = requests.get(url, headers=headers).text
# 转换
html = etree.HTML(data)
# 3.解析数据 xpath 取出来的数据是一个列表。
# 排名
rank = html.xpath('//td[@class="td-01 ranktop"]/text()')
# 事件
affair = html.xpath('//td[@class="td-02"]/a/text()')
affair.pop(0) # 忽略微博热搜的置顶推荐内容。 # .pop(n) :删除列表第 n+1 个元素。
# 热度
view = html.xpath('//td[@class="td-02"]/span/text()')
# 链接
link = html.xpath('//td/a/@href')
link_try = html.xpath('//td/a/@href_to')
link.pop(0)
# 处理链接数据(因为链接的 html 位置可能存在不同的地方,所以做了以下判断)
index = 0
for i, sku in enumerate(link): # 这里的 i 和 sku 是什么?这里的 i 和最后保存时最后的代码里的 i 一样吗?
if sku == "javascript:void(0);":
link[i] = link_try[index]
index += 1
# 4.保存数据为 csv。
date = datetime.now().strftime('%Y-%m-%d %H-%M-%S')
# 删除没有热度的热搜(隐藏的热搜)
rank_new = copy.deepcopy(rank)
for r in range(len(rank_new)):
if not rank_new[r].isdigit():
rank.remove(rank_new[r])
del affair[r]
del link[r]
with open('./' + date + '.csv', 'w', newline='', encoding='utf-8-sig')as f:
writer = csv.writer(f)
writer.writerow(['排名', '事件', '热度', '链接'])
for i, rank in enumerate(rank):
writer.writerow([rank, affair[i], view[i], 'https://s.weibo.com' + link[i]])
# 5.睡眠120秒。
time.sleep(120)
except:
print(time.strftime("%Y-%m-%d %X"))
print("requests speed so high,need sleep!")
time.sleep(10)
print("continue...")
while True:
doSth()
回答:
from selenium import webdriverimport time
DRIVER_PATH = '' # chromdriver的地址
def selenium_chrome_test(url):
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument("--no-sandbox")
# 启用无痕模式
chrome_options.add_argument("--incognito")
chrome_options.add_argument("--disable-gpu")
# 取消自动软件控制提示
chrome_options.add_argument("disable-infobars")
prefs = {
'profile.default_content_setting_values': {'notifications': 2}
}
chrome_options.add_experimental_option("prefs", prefs)
global browser
browser = webdriver.Chrome(DRIVER_PATH, chrome_options=chrome_options)
browser.maximize_window()
browser.get(url)
time.sleep(5)
eles = browser.find_elements_by_xpath('//tbody//tr')
for ele in eles:
item_datas = ele.find_elements_by_xpath('./td')
title = item_datas[1].text
print(title)
href = item_datas[1].find_element_by_xpath('./a').get_attribute('href')
print(href)
if __name__ == '__main__':
url = 'https://s.weibo.com/top/summary?cate=realtimehot'
selenium_chrome_test(url=url)
以上是 微博热搜是爬取不了吗? 的全部内容, 来源链接: utcz.com/p/938120.html