python如何爬取七猫小说大全(单纯想学习如何绕过七猫小说大全的反爬机制)
我在学习爬虫的时候,想用七猫小说大全练手。因为想了解它的反爬机制。
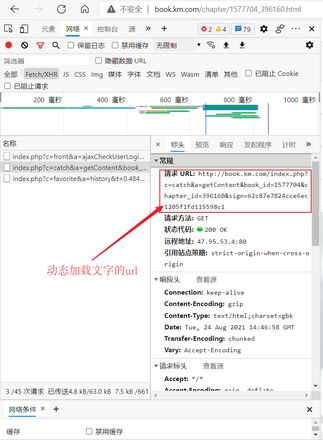
但是当我得到ajax的原url去浏览器中访问的时候,得到的响应却是error,不是状态码,说明的确得到了响应,但为什么无法获得我想要的数据呢?
求各位大佬指点一下怎么用python解决这个问题。
小说页的url:
http://book.km.com/chapter/15...
ajax中的url:
http://book.km.com/index.php?...

问题描述
问题出现的环境背景及自己尝试过哪些方法
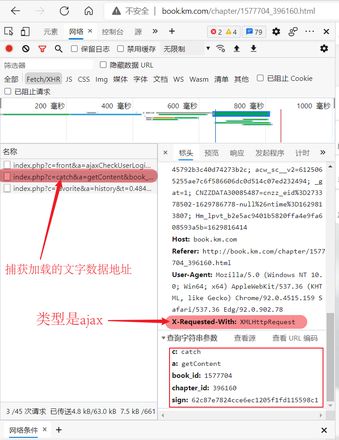
注意:当你打开网页后,要往后翻一、两章才会在刷出目标ajax
相关代码
粘贴代码文本(请勿用截图)
你期待的结果是什么?实际看到的错误信息又是什么?
回答:
要分为两步:
- 访问章节地址,获取 sign,并保留 Cookie
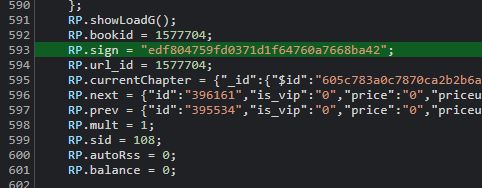
- 再进行请求 Ajax 地址,带上保留的 Cookie,地址为:
http://book.km.com/index.php?c=catch&a=getContent&book_id=<书籍编号>&chapter_id=<章节编号>&sign=<第一步得到的sign>
以上是 python如何爬取七猫小说大全(单纯想学习如何绕过七猫小说大全的反爬机制) 的全部内容, 来源链接: utcz.com/p/938071.html