为什么爬虫老是会被对方拉黑?

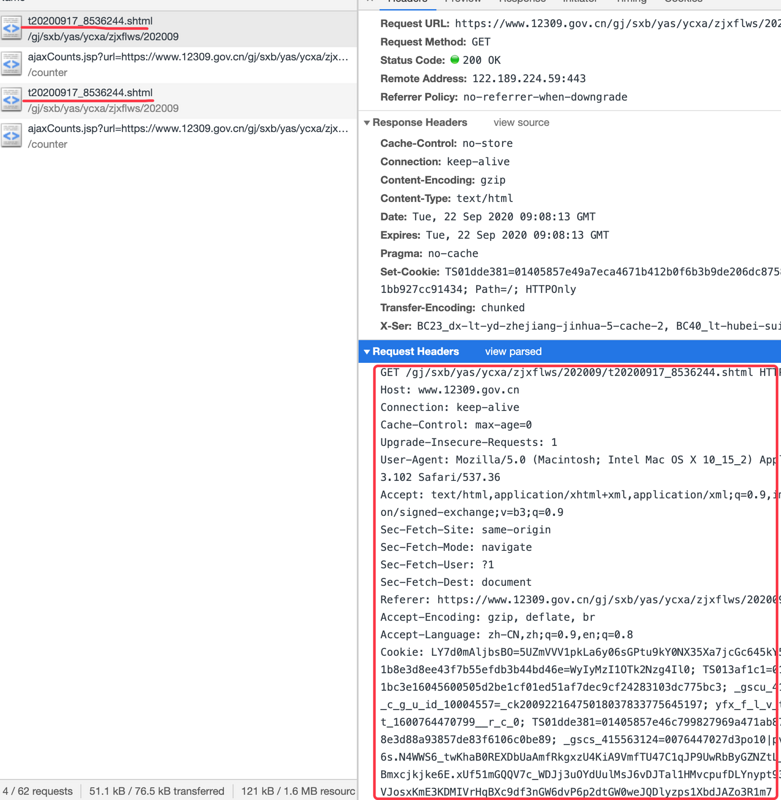
头部信息我就加了两条,一个是User-Agent,一个是cookie,请求用的是request
User-Agent会加入一段浏览器标识,我想这样就可以骗过对方。没想到,刚开始是可以爬到信息的,几天后请求返回一片空白,要么就报403。
本地启动项目可以爬,服务器去爬的话就爬不到,我想我的服务器ip已经被对方拉黑了
我想知道对方是怎么发现我在爬他的网站的呢,遇到这种情况怎么处理呢?还有没有比较好的伪装方法?
回答:
请求太多了呗。。。。恶意用户 直接封
回答:
请求频率太高,次数太多,影响网站正常运行了吧
回答:
虚假的武术家:我的闪电五连鞭可以 blablabla……
真正的武术家:为了这场比赛,我和教练还有对练准备了有半年之久,一直在研究对手以前的打法,并且不断猜测对手可能会如何对付我,有针对性地设计我们的打法。
散打比赛是人与人的对抗,爬虫与反爬虫也是,双方都要在对抗中不断进化。武术没有绝招可以用到老,爬虫也没有任何“比较好的伪装方法”可以给你一直用,最好的办法是不断换服务器 IP,这玩意有人卖的。
或者你爬虫不要太过分,把频率降到比人正常访问低的水平,不把人家羊毛薅秃了,人家可能就不会针对你。
以上是 为什么爬虫老是会被对方拉黑? 的全部内容, 来源链接: utcz.com/p/938054.html