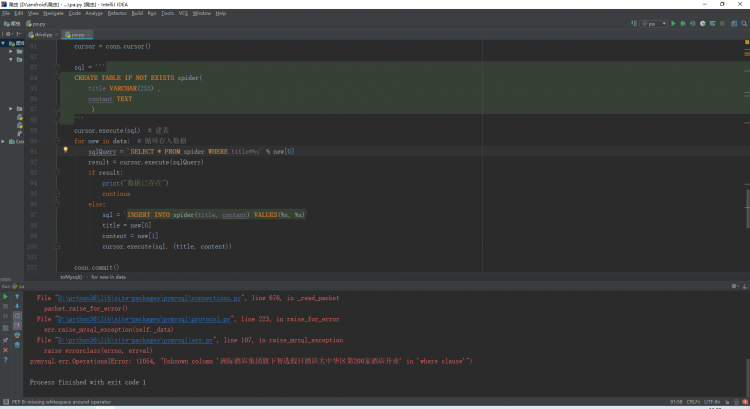
为什么这个字符串赋值给了一个变量,就不能转码了

取出这个‘\xe7\x9b\xb8\xe5\x85\xb3\xe7\xbb\x93\xe6\x9e\x9c\xe7\xba\xa60\xe4\xb8\xaa’字符串是可以在这后面加.encode("raw_unicode_escape").decode("utf-8"),实现转码的。但是在原来的字符串变量里就不行。。。
import reimport requests
response=requests.get('http://so.eastmoney.com/web/s?keyword=000850&pageindex=1')
r=re.findall('<div class="count">((?:.|n)*?)<',str(response.content))
print(r[0].encode("raw_unicode_escape").decode("utf-8"))
print(type(r[0]))
print('xe7x9bxb8xe5x85xb3xe7xbbx93xe6x9ex9cxe7xbaxa60xe4xb8xaa'.encode("raw_unicode_escape").decode("utf-8"))
结果是
\xe7\x9b\xb8\xe5\x85\xb3\xe7\xbb\x93\xe6\x9e\x9c\xe7\xba\xa60\xe4\xb8\xaa相关结果约0个
为啥这个r[0]就不能直接变成这种格式啊
回答:
闲着没事找了一下,真找到了个方法?
r[0] = ...// 此处使用 latin1 和 raw_unicode_escape 编码效果相同
bytes(r[0], 'utf-8').decode('unicode_escape').encode('latin1').decode('utf-8')
>>> '相关结果约0个'
题主转不了的原因是因为在使用正则表达式时,使用了 ...,str(response.content)) 从而导致后续的操作实际上是在对普通的字符串'\\xe7\\x9b\\xb8...' 进行转换(注意这里有 \\ 转义符出现了)。
而在直接执行 '\xe7\x9b\xb8...\xaa'.encode(.... 时实际上是对十六进制的字符串(这个描述可能不太准确)进行了转换。
In [1]: a = '\xe7\x9b\xb8\xe5\x85\xb3\xe7\xbb\x93\xe6\x9e\x9c\xe7\xba\xa60\xe4\xb8\xaa'In [2]: a
Out[2]: 'ç\x9b¸å\x85³ç»\x93æ\x9e\x9c约0个'
In [3]: b = '\\xe7\\x9b\\xb8\\xe5\\x85\\xb3\\xe7\\xbb\\x93\\xe6\\x9e\\x9c\\xe7\\xba\\xa60\\xe4\\xb8\\xaa'
In [4]: b
Out[4]: '\\xe7\\x9b\\xb8\\xe5\\x85\\xb3\\xe7\\xbb\\x93\\xe6\\x9e\\x9c\\xe7\\xba\\xa60\\xe4\\xb8\\xaa'
In [5]: c = bytes(b, 'utf-8').decode('unicode_escape')
In [6]: c
Out[6]: 'ç\x9b¸å\x85³ç»\x93æ\x9e\x9c约0个'
In [7]: c == a
In [7]: True
以上是 为什么这个字符串赋值给了一个变量,就不能转码了 的全部内容, 来源链接: utcz.com/p/937931.html