如何基于 Kafka 打造高可靠、高可用消息平台?

Kafka 是当前非常流行的一个消息系统,最初用作 LinkedIn 的活动流式数据和运营数据处理管道的基础。活动流式数据主要包括页面访问量PV、访问内容以及检索内容等。运营数据指的是服务器的性能数据(CPU、IO 使用率、请求时间、服务日志等等数据)。这些数据通常的处理方式是先把各种活动以日志的形式写入某种文件,然后周期性地对这些文件进行统计分析。
近年来,随着互联网的快速发展,活动和运营数据处理已经成为网站软件产品特性中一个至关重要的组成部分,需要一套庞大的基础设施对其提供支持。

Kafka 是一个分布式、支持分区的、多副本的,基于 Zookeeper 协调的分布式消息系统,现已捐献给 Apache 基金会。它最大的特性就是可以实时处理大量数据并且支持动态水平扩展,这样的特性可以满足各种需求场景:比如基于 Hadoop 的批处理系统、低延迟的实时系统、Storm/Spark 流式处理引擎,日志处理系统,消息服务等等。

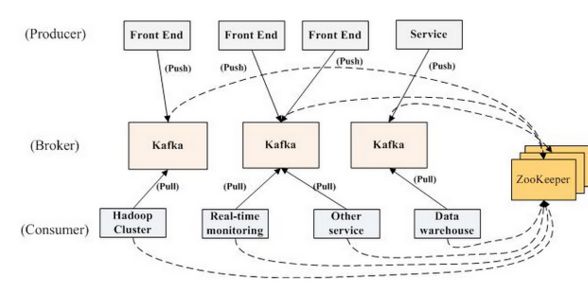
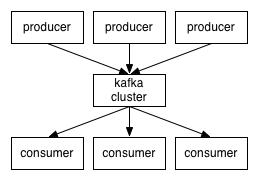
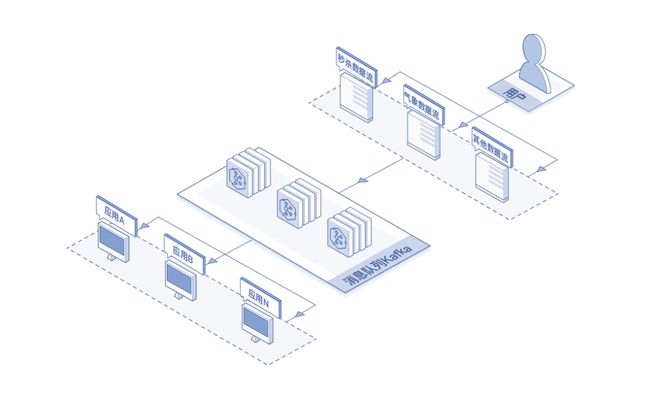
Kafka 架构如上图所示,本质就是生产-存储-消费,主要包含以下四个部分:
- Producer Cluster:生产者集群,负责发布消息到 Kafka broker,一般由多个应用组成。
- Kafka Cluster:Kafka 服务器集群。这里就是 Kafka 最重要的一部分,这里负责接收生产者写入的数据,并将其持久化到文件存储里,最终将消息提供给 Consumer Cluster。
- Zookeeper Cluster:Zookeeper 集群。Zookeeper 负责维护整个 Kafka 集群的 Topic 信息、Kafka Controller 等信息。
- _Consumer Cluster_:消费者集群,负责从 Kafka broker 读取消息,一般也由多个应用组成,获取自己想要的信息。
Kafka 相关概念解释
- Broker Kafka 集群包含一个或多个服务器,这种服务器被称为 broker;
- Topic 每条发布到 Kafka 集群的消息都有一个类别,这个类别被称为 Topic。(物理上不同 Topic 的消息分开存储,逻辑上一个 Topic 的消息虽然保存于一个或多个 broker 上但用户只需指定消息的 Topic 即可生产或消费数据而不必关心数据存于何处);
- Partition 是物理上的概念,每个 Topic 包含一个或多个 Partition;
- Producer 负责发布消息到 Kafka broker;
- Consumer 消息消费者,向 Kafka broker 读取消息的客户端;
- Consumer Group 每个 Consumer 属于一个特定的 Consumer Group(可为每个 Consumer 指定 group name,若不指定 group name 则属于默认的 group)。
在 Kafka 架构设计里,无论是生产者、还是消费者、还是消息存储,都可以动态水平扩展,从而提高整个集群的吞吐量、可扩展性、持久性和容错性,Kafka生来就是一个分布式系统,这赋予了它以下特性:
- 高吞吐量、低延迟:Kafka可以以较低的资源消耗处理每秒上百MB的消息吞吐量,而它的延迟最低只有几毫秒。
- 可扩展性:Kafka集群支持动态水平扩展。
- 持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失。
- 容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)。
- 高并发:支持数千个客户端同时读写。

目前越来越多的开源分布式处理系统如 Cloudera、Apache Storm、Spark、Flink 等都支持与 Kafka 集成,Kafka 可被广泛应用于以下场景中:
消息系统 :异步解耦生产者和消费者,削峰填谷波动的流量峰值。
_日志聚合:_可以用 Kafka 收集各种服务的操作日志,通过 Kafka 以统一接口服务的方式开放给各种消费者,可以使用 Hadoop 等其他系统化的存储和分析系统对聚合的日志进行统计分析。
用户活动跟踪: Kafka 经常被用来记录 web 用户或者 app 用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到 Kafka 中,然后订阅者通过订阅这些 topic 来做实时的监控分析,做离线分析和挖掘。
运营指标:Kafka 也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和监控。
流式处理:Kafka 可以很好地支持离线数据、流式数据的处理,并能够方便地进行数据聚合、分析等操作。比如 Spark streaming 和 Storm。

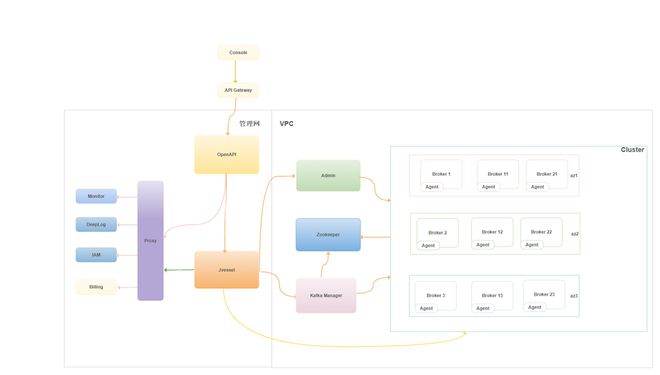
京东智联云消息队列 Kafka 版不仅托管了开源的 Apache Kafka,做到了用户原有业务代码无需改造,即可无缝迁移上云,并且还增强了对于 Kafka 集群的创建、管理、运维和监控,用户通过京东智联云消息队列 Kafka 版部署,可以获得以下优势:
多版本创建
支持Kafka V0.10、V1.0、V2.4多版本创建,并且支持预付费和后付费两种模式。三个大版本的支持方便使用kafka的用户无缝迁移上云,后付费的模式支持用户进行测试试用,不必产生机器成本的费用,免去多次部署的麻烦。
弹性扩容
轻松扩展,方便快捷。用户可根据资源使用情况按需扩容,不影响现有业务的同时以满足业务增长需求。避免了用户自行搭建Kafka进行扩容的复杂操作和业务风险。
管理组件
用户创建的每个 Kafka 集群都配置了 Kafka Manager,方便用户进行界面化、可视化的集群管理,免去了API调用或者命令行工具的复杂操作。
运维监控
集群级别免运维,配备健康检查,不健康的状态自动 failover,无需用户运维,即可保证服务可用性。并且对集群状态进行监控,支持多维度的监控预警。免去了服务不可用但是使用方无感知的担忧。

下面我们看一下通过京东智联云消息队列 Kafka,是如何构建高可靠高吞吐 Kafak 服务的?
1
提高京东智联云 Kafka 的吞吐量
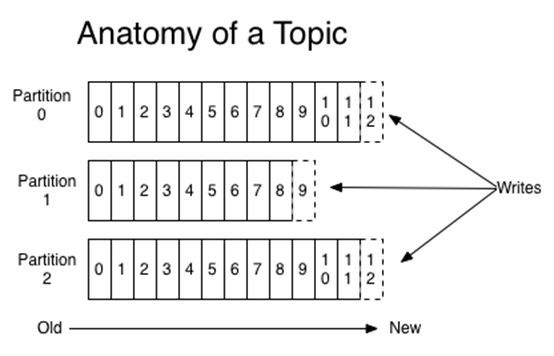
Kafka 中主题 topic 作为主要接受消息的载体,一般会分成一个或多个分区 partition,每个 partiton 相当于是一个子 queue,多个 partition 就相当于多个子 queue 在同时工作进行写盘和交互处理,因此增加 partition 可以增加单个主题 topic 的吞吐量。
在物理结构上,每个 partition 对应一个物理的文件,Kafka 中会把消息持久化到本地文件系统中,并且保持 o(1) 极高的效率。磁盘的 IO 读写是非常耗资源的性能,所以提高磁盘的 iops 和吞吐量,可以提高消息写入磁盘的速度,相应的提高吞吐。
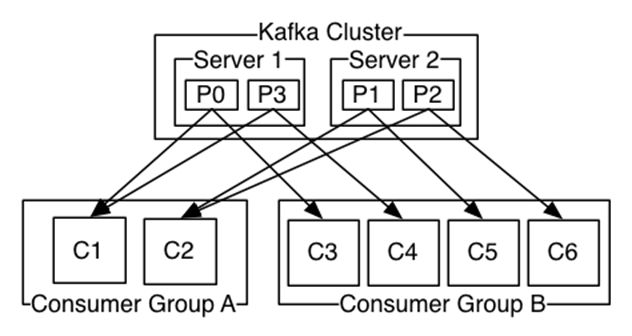
Kafka 中的主题都是由消费组 consumer group 来消费的。如果这个 consumer group 里面 consumer 的数量小于 topic 里面 partition 的数量,就会有 consumer thread 同时处理多个 partition。如果这个 consumer group 里面 consumer 的数量大于 topic 里面 partition 的数量,多出的 consumer thread 就会闲置,剩下的是一个 consumer thread 处理一个 partition,这就造成了资源的浪费,因为一个 partition 不可能被两个 consumer thread 去处理。
建议:
1)增加分区数 partition 可以有效提高消息的吞吐量,并且分区数最好是集群处理节点 broker 的整数倍,这样每个副本分配到的分区数比较均匀;
2)采用高 iops 和高吞吐的磁盘规格和 SSD 类型的磁盘;
3)增加生产者 producer 和消费者 consumer 的数量,并且消费者的数量最好可以和分区数相等。
2
提高京东智联云 Kafka 的可靠性
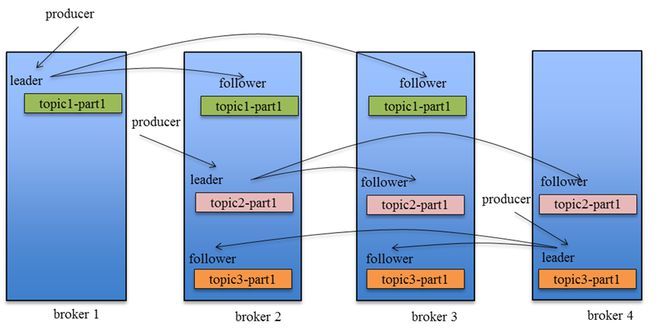
Kafka 主题 topic 的副本数即备份 replica 的个数。如果副本数为 1 , 即使 Kafka 节点机器有多个,当该副本所在的机器宕机后,对应的数据也会访问失败。但副本数不是越多越好,副本数不能多于 Kafka 中处理节点 broker 的数量,更多的副本数在进行数据同步的时候会影响服务的性能。
当主题有了多副本之后,发送消息时候副本数据同步策略也影响着数据的高可靠性,主要由 ack 这个参数来控制。
- 当 ack=1,表示 producer 写 leader 成功后,broker 就返回成功,无论其他的 follower 是否写成功;
- 当 ack=2,表示 producer 写 leader 和其他一个 follower 成功的时候,broker 就返回成功,无论其他的 partition follower 是否写成功;
- 当 ack=-1,表示只有 producer 全部写成功的时候,才算成功,kafka broker才返回成功信息。
可见当 ack=-1 时候,数据的可靠性肯定是最好的,但是这会影响到服务的可用,因为必须所有的 follower 都写入成功才算成功,一个 follow 出现问题就会导致服务不可用。
建议:
1)当创建 Kafka 主题时,如果对数据可靠性有要求建议设置主题 topic 的副本数不少于三副本;
2)设置发送消息 ack 参数的时候,建议设置半数以上的副本成功就算发送成功即可,这样可以兼顾消息的可靠性也不会降低服务的可用性;
3)发送消息的时候选择同步或者异步的方式,关心消息的发送结果并且对于发送失败的消息进行处理。
京东智联云消息队列 Kafka 在部署的时候还可以做到节点反亲和,使得真正 topic 的多副本能做到跨可用区,做到集群和 topic 都能保持跨可用区的可用性。
通过以上内容,你应该已经知道如何通过使用京东智联云消息队列 Kafka,构建一个高可靠高吞吐的 Kafka 消息服务了,如果想更近一步体验该产品,请点击【阅读原文】链接体验试用。
参考资料:
*《Confluent官网》https://www.confluent.io/blog...
*《Kafka 设计解析(一):Kafka 背景及架构介绍》
https://www.infoq.cn/article/...
*《Kafka(三)Kafka的高可用与生产消费过程解析》
https://www.cnblogs.com/frank...
以上是 如何基于 Kafka 打造高可靠、高可用消息平台? 的全部内容, 来源链接: utcz.com/p/937875.html