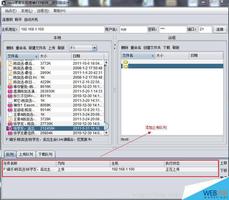
想将爬取到的图片放到新建的文件夹里,结果创建了文件夹,和图片在同一级目录
OO.jpg") 求指点下怎么解决这个问题
求指点下怎么解决这个问题
import requestsfrom bs4 import BeautifulSoup
import urllib
import os
import re
def filename(element): path = 'D:/abc'
title = element
new_path = os.path.join(path,title)
if not os.path.isdir(new_path):
os.makedirs(new_path)
return new_path
def getHTML(url): r = requests.get(url)
r.encoding = 'utf-8'
return r.text
def HTMLinfo(infolist,html): soup = BeautifulSoup(html,'lxml')
picdivs=soup.find_all('div',attrs={'class':'p_postlist'})
for picdiv in picdivs:
imgs =picdiv.find_all('img',attrs={'class':'BDE_Image'})
for img in imgs:
src = img['src']
infolist.append(src)
def downLoadpics(new_path,infolist): for src in infolist:
path = new_path + src.split('/')[-1]
urllib.request.urlretrieve(src,path)
def main(): firsturl = 'http://tieba.baidu.com/p/5879277457'
infolist = []
depth = 2
element = firsturl.split('/')[-1]
PATH = filename(element)
for i in range(1,depth+1):
try:
url = firsturl + '?p=' + str(i)
html = getHTML(url)
HTMLinfo(infolist,html)
downLoadpics(PATH,infolist)
except:
continue
main()
回答:
def downLoadpics(new_path,infolist): for src in infolist:
path = new_path + src.split('/')[-1]
urllib.request.urlretrieve(src,path)
这里的的path = new_path + src.split('/')[-1] 中间少了"/"
可以改为path=os.path.join(new_path,src.split('/')[-1])
以上是 想将爬取到的图片放到新建的文件夹里,结果创建了文件夹,和图片在同一级目录 的全部内容, 来源链接: utcz.com/p/937723.html