请教一下python爬虫的编码问题解决“思路”

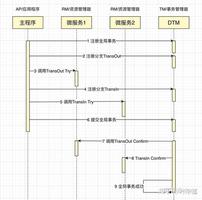
如果爬虫的response.text遇到乱码问题,应该用什么思路去找到正确的编码来解决问题呢?
请大佬指教
回答:
有个奇葩的思路我发现,做爬虫的时候大家都喜欢把request.headers照搬下来,我发现我照搬下来就会乱码,我我只留个user-agent和cookie反而不乱码了
回答:
我一般写爬虫的时候不会去特意指定编码,因为它网页的编码声明跟它实际网页的编码是不一致的。这就很头疼了。
为了应对这个问题,response对象有个属性可以根据网页中大部分编码分析出网站的编码方式,就可以获得网页的编码了。
import requestsdef get_html(url):
try:
r = requests.get(url)
r.encoding = r.apparent_encoding
return t.text
except Exception as e:
print(e)
return None
回答:
试试这个
pip install chardet
回答:
r = requests.get(url)r.encoding = 'utf-8'
print r.text
回答:
找html的head,大部分网站的head都有编码
回答:
解码的时候使用response.text大概率会出问题,试一下用response.content。
response.encoding = response.apparent_encoding也是个不错的选择
以上是 请教一下python爬虫的编码问题解决“思路” 的全部内容, 来源链接: utcz.com/p/937700.html