多进程提取返回值比较耗时,请问该如何修改?
各位大佬我在用以下代码进行多进程运算,多了几行提取返回值就特别耗时,请问是什么原因,该如何修改?
`
def deal_many_data(data_all,new_data): sim_all = 0 (初始化)
count = 0 (初始化)
text = list(set(data_all['text']))
if len(text) >= 10:
newlist = random.sample(list(range(0,len(text))),10)
else:
newlist = list(range(0,len(text)))
for index in newlist:
data = text[index]
sim = sentence_similarity(data,new_data)
sim_all += sim
count += 1
a = sim_all/count (计算总的相似度)
return int(a)
from multiprocessing import Pool
import multiprocessing
from functools import partial
if __name__ == '__main__':
data3 =data2[:3]
start_time=time.time()
for item in data3:
if item['autn:content']['DOCUMENT'].get('DIS_ORG') != None:
##创建多进程
with multiprocessing.Pool(processes=10) as pool:
results = []
data_all1 = list(data_all.values())#字典转换列表
title = item['autn:content']['DOCUMENT']['DRETITLE']['$'].strip().replace(' ','')
content = item['autn:content']['DOCUMENT']['DRECONTENT']['$'].strip().replace('\n','').replace(' ','')
new_data = title + ' ' + content
#偏函数传入多个参数
partial_func = partial(deal_many_data, new_data=new_data)
for i in data_all1:
results.append(pool.apply_async(partial_func, (i,)))#获取返回值储存
#提取返回值
out = []
for i in results:
out.append(i.get())
end = time.time()
print ('finally cost time %ss'%(end-start_time))`
最终耗时100s+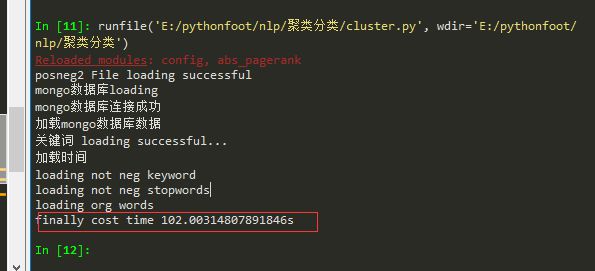
而当去掉
`
#提取返回值out = []
for i in results:
out.append(i.get())`
这句代码时
``
def deal_many_data(data_all,new_data): sim_all = 0 (初始化)
count = 0 (初始化)
text = list(set(data_all['text']))
if len(text) >= 10:
newlist = random.sample(list(range(0,len(text))),10)
else:
newlist = list(range(0,len(text)))
for index in newlist:
data = text[index]
sim = sentence_similarity(data,new_data)
sim_all += sim
count += 1
a = sim_all/count (计算总的相似度)
return int(a)
from multiprocessing import Pool
import multiprocessing
from functools import partial
if __name__ == '__main__':
data3 =data2[:3]
start_time=time.time()
for item in data3:
if item['autn:content']['DOCUMENT'].get('DIS_ORG') != None:
##创建多进程
with multiprocessing.Pool(processes=10) as pool:
results = []
data_all1 = list(data_all.values())#字典转换列表
title = item['autn:content']['DOCUMENT']['DRETITLE']['$'].strip().replace(' ','')
content = item['autn:content']['DOCUMENT']['DRECONTENT']['$'].strip().replace('\n','').replace(' ','')
new_data = title + ' ' + content
#偏函数传入多个参数
partial_func = partial(deal_many_data, new_data=new_data)
for i in data_all1:
results.append(pool.apply_async(partial_func, (i,)))#获取返回值储存
end = time.time()
print ('finally cost time %ss'%(end-start_time))``
耗时不到1s,请问这是为何,我想获取返回值,该如何解决,提高效率。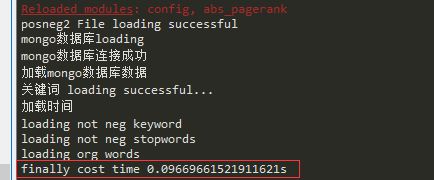
回答:
耗时不到1s,请问这是为何
apply_ansyc 只是布置任务,并不会等任务完成。你没有 get ,计算的时间只是你把任务分配下去所用的时间,这些任务实际并没有完成(甚至有些任务可能只是布置下去了,根本都还没有开始)。
以上是 多进程提取返回值比较耗时,请问该如何修改? 的全部内容, 来源链接: utcz.com/p/937676.html